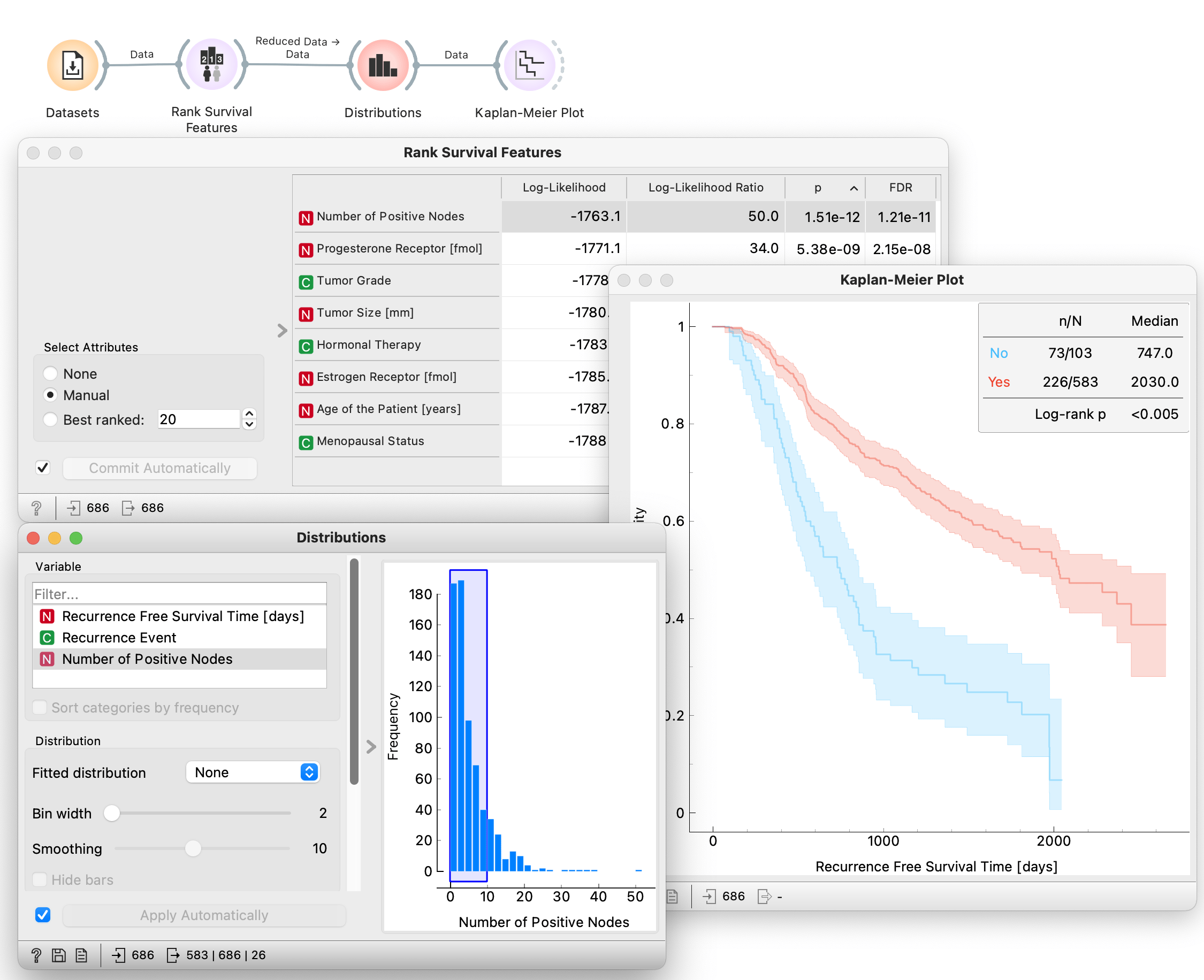
Rank Survival Features
Rank features according to univariate estimate of importance by Cox regression model.
Inputs
- Data: reference survival dataset
Outputs
- Reduced data: data comprised of selected features
Rank Survival Features receives a survival dataset on the input and ranks each feature according to a univariate estimate of importance by the Cox regression model. It provides four different statistical measures to rank and report on the importance of a feature: Log-Likelihood, Log-Likelihood Ratio, p-value and FDR. The user can select any feature or set of features from the ranked list, and the widget outputs a dataset comprised of only selected features.
Example
In this example we use Rank Survival Features to discover the most important survival feature in the German breast cancer study group 2. We load the already available data with the use of Datasets and connect it to Rank Survival Features. We sort the features according to the p-value and select the top feature (with the smallest p-value), Number of Positive Nodes. This way the widget outputs a dataset comprised only of the selected feature. In this example we proceed to display the distribution of the feature of interest and select part of the distribution to define the target cohort. Interactively selecting patients in the distribution plot allows us to rapidly generate new groups of patients. We can visualize and compare the survival curves of the generated cohort to that of other patients, using the Kaplan-Meier Plot.