Tile File
Read data tile-by-tile from input file(s), preprocess the spectra, and send a data table to the output.
Inputs
- Preprocessor: A preprocessor list from the Preprocess Spectra widget
Outputs
- Data: preprocessed dataset read from the input file(s)
The Tilefile widgets loads data from compatible mosaic spectral images and applies the supplied preprocessor(s) to the data. The preprocessing is applied one mosaic tile at a time, and the resulting processed dataset is combined into a single Data Table.
At least one of the preprocessors should reduce the dataset size (such as Cut, Integrate) to take advantage of this file loader and reduce total memory usage.
By default, the widget will not load the dataset automatically. This prevents loading a large dataset into memory before the desired preprocessor chain is configured. Press the "Reload" button to load the data.
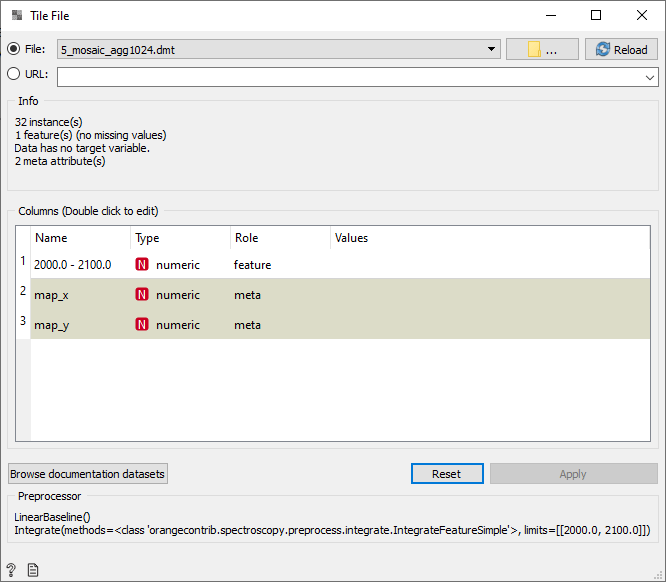
- Browse through previously opened data files, or load any of the sample ones.
- Browse for a data file.
- (Re)loads currently selected data file.
- Insert data from URL addresses.
- Information on the preprocessed dataset: dataset size, number and types of data features.
- Additional information on the features in the preprocessed dataset. Features can be edited by double-clicking on them. The user can change the attribute names, select the type of variable per each attribute (Continuous, Nominal, String, Datetime), and choose how to further define the attributes (as Features, Targets or Meta). The user can also decide to ignore an attribute.
- Browse documentation datasets.
- Information on the applied preprocessor list.
- Produce a report.
Example
Here is a simple example on how to use the Tilefile widget. We configured a preprocessor list in Preprocess Spectra and connected the Preprocessor output to the input on the Tilefile widget. We have loaded a mosaic data set that was stored on our local machine. We used the folder icon to access the file and load them. We check the preprocessor that will be applied and press "Reload" to load the data. Now information about the preprocessed dataset is displayed in the info box and domain editor.
We can observe the preprocessed data in the HyperSpectra widget or in a Data Table.
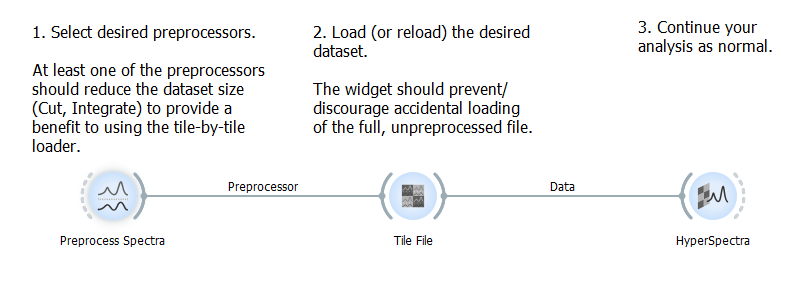
This example workflow can be found in Help/Example Workflows.