Hierarchical Clustering
Groups items using a hierarchical clustering algorithm.
Inputs
- Distances: distance matrix
- Data Subset:
Outputs
- Selected Data: instances selected from the plot
- Data: data with an additional column showing whether an instance is selected
The widget computes hierarchical clustering of arbitrary types of objects from a matrix of distances and shows a corresponding dendrogram. Distances can be computed with the Distances widget.
 {width=600px}
{width=600px}
- The widget supports the following ways of measuring distances between clusters:
- Single linkage computes the distance between the closest elements of the two clusters
- Average linkage computes the average distance between elements of the two clusters
- Weighted linkage uses the WPGMA method
- Complete linkage computes the distance between the clusters' most distant elements
- Ward linkage computes the increase of the error sum of squares. In other words, the Ward's minimum variance criterion minimizes the total within-cluster variance.
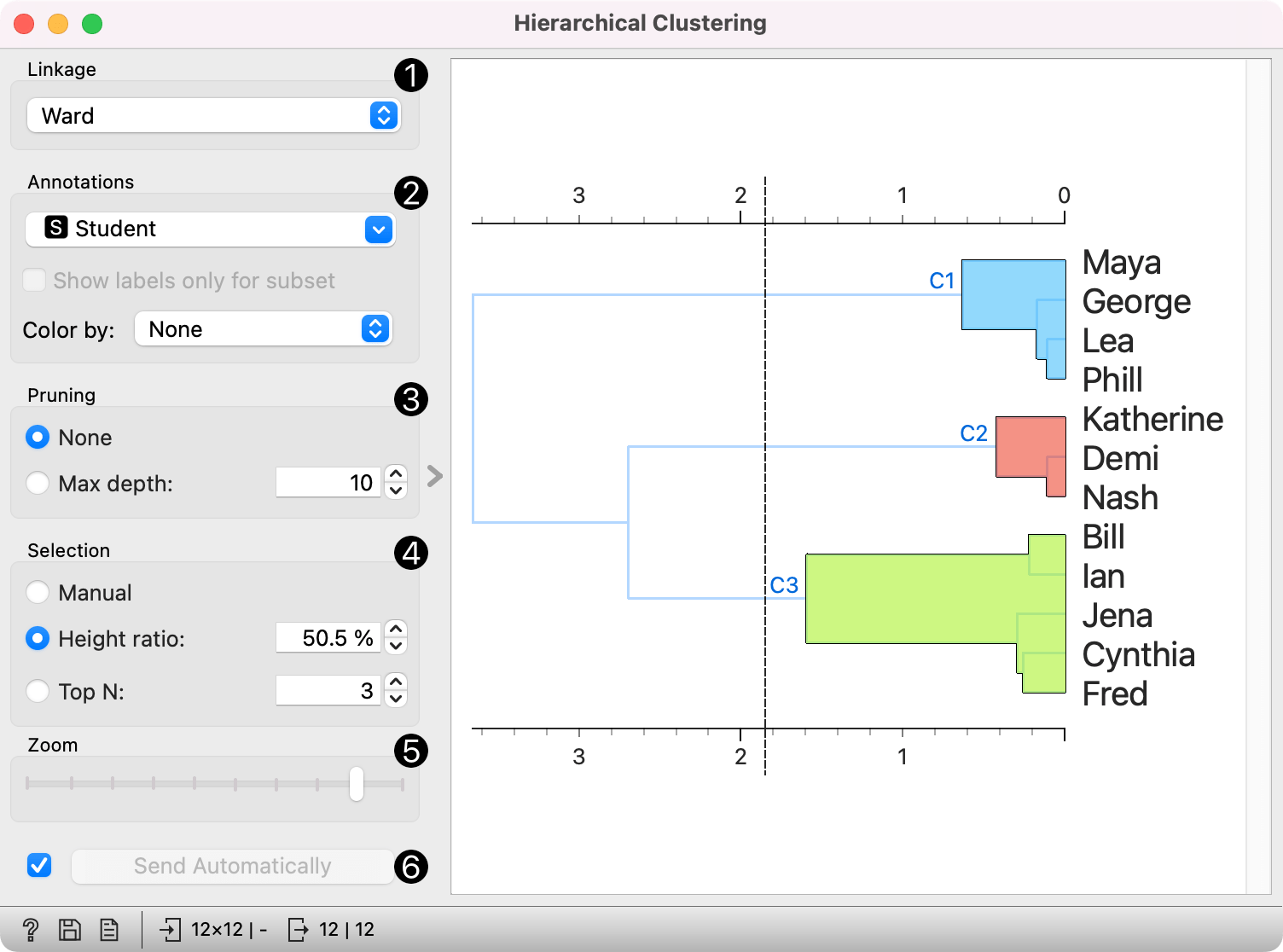
- Labels of nodes in the dendrogram can be chosen in the Annotation box. Show labels only for subset exposes only labels passed as instances in the Data Subset input.
- Large dendrograms can be pruned in the Pruning box by selecting the maximum depth of the dendrogram. This only affects the display, not the actual clustering.
- The widget offers three different selection methods:
- Manual (Clicking inside the dendrogram will select a cluster. Multiple clusters can be selected by holding Ctrl/Cmd. Each selected cluster is shown in a different color and is treated as a separate cluster in the output.)
- Height ratio (Clicking on the bottom or top ruler of the dendrogram places a cutoff line in the graph. Items to the right of the line are selected.)
- Top N (Selects the number of top nodes creating N clusters.)
- Use Zoom to zoom in or out.
- If Send Selected Automatically is on, the data subset is communicated automatically, otherwise you need to press Send Selected.
To output clusters, click on the ruler at the top or the bottom of the visualization. This will create a cut-off for the clusters.
Examples
Cluster selection and projections
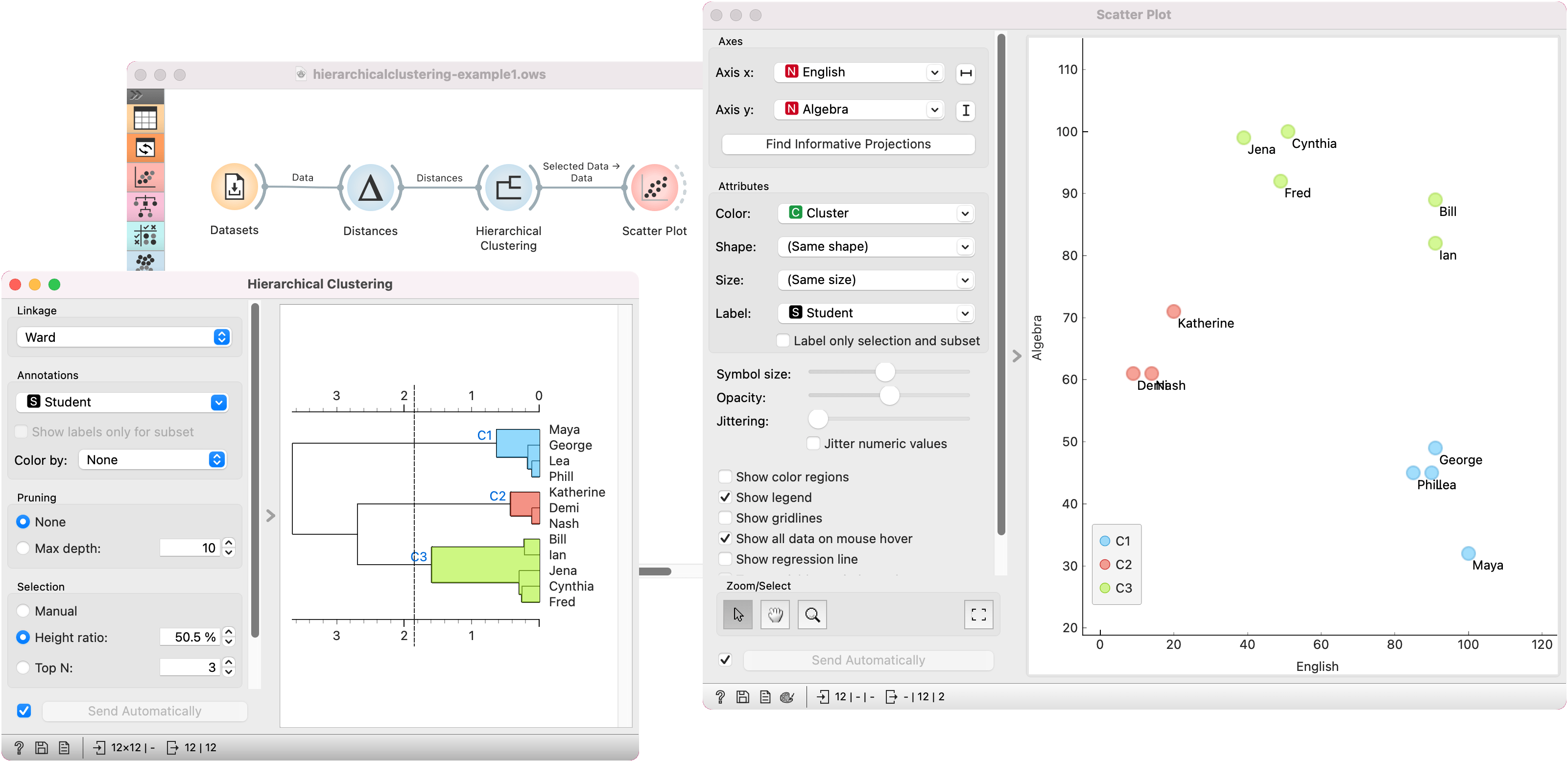
We start with the Grades for English and Math data set from the Datasets widget. The data contains two numeric variables, grades for English and for Algebra.
Hierarchical Clustering requires distance matrix on the input. We compute it with Distances, where we use the Euclidean (normalized) distance metric.
Once the data is passed to the hierarchical clustering, the widget displays a dendrogram, a tree-like clustering structure. Each node represents an instance in the data set, in our case a student. Tree nodes are labelled with student names.
To create the clusters, we click on the ruler at the desired threshold. In this case, we chose three clusters. Since our dataset comes in 2D, we pass those clusters to Scatter Plot, which shows a plot of data instances, colored by cluster label.
Cluster explanation
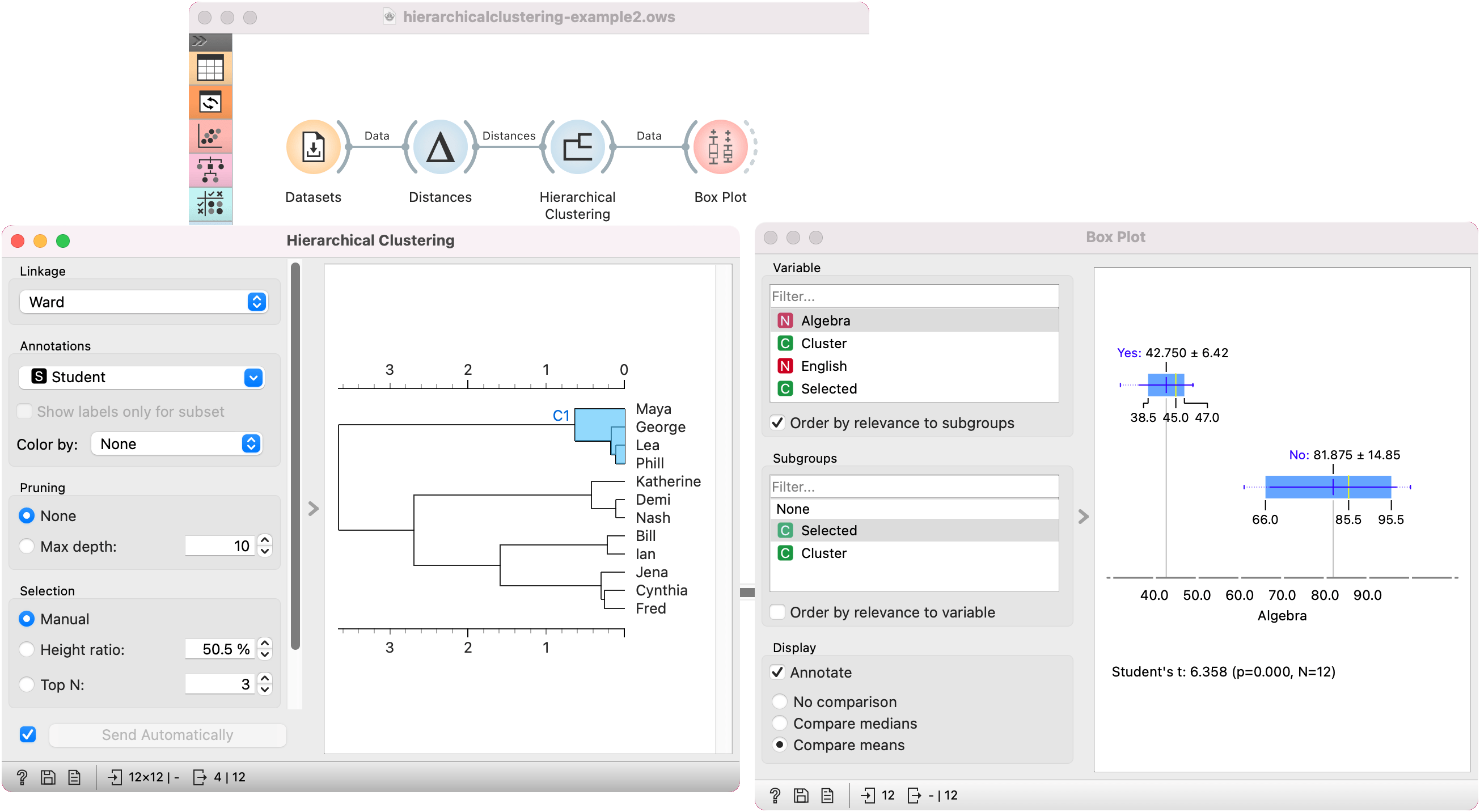
In the second example, we continue with the Grades for English and Math data. Say we wish to explain what characterizes the cluster with Maya, George, Lea, and Phill.
We select the cluster in the dendrogram and pass the entire data set to Box Plot. Note that the connection here is Data, not Selected Data. To rewire the connection, double-click on it.
In Box Plot, we set Selected variable as the Subgroup. This will split the plot into selected data instances (our cluster, labeled as Yes) and the remaining data (labeled as No). Next, we use Order by relevance to subgroups option, which sorts the variables according to how well they distinguish between subgroups. It turns out, that our cluster contains students who are bad at math (they have low values of the Algebra variable).