Select by Data Index
Match instances by index from data subset.
Inputs
- Data: reference data set
- Data Subset: subset to match
Outputs
- Matching data: subset from reference data set that matches indices from subset data
- Unmatched data: subset from reference data set that does not match indices from subset data
- Annotated data: reference data set with an additional column defining matches
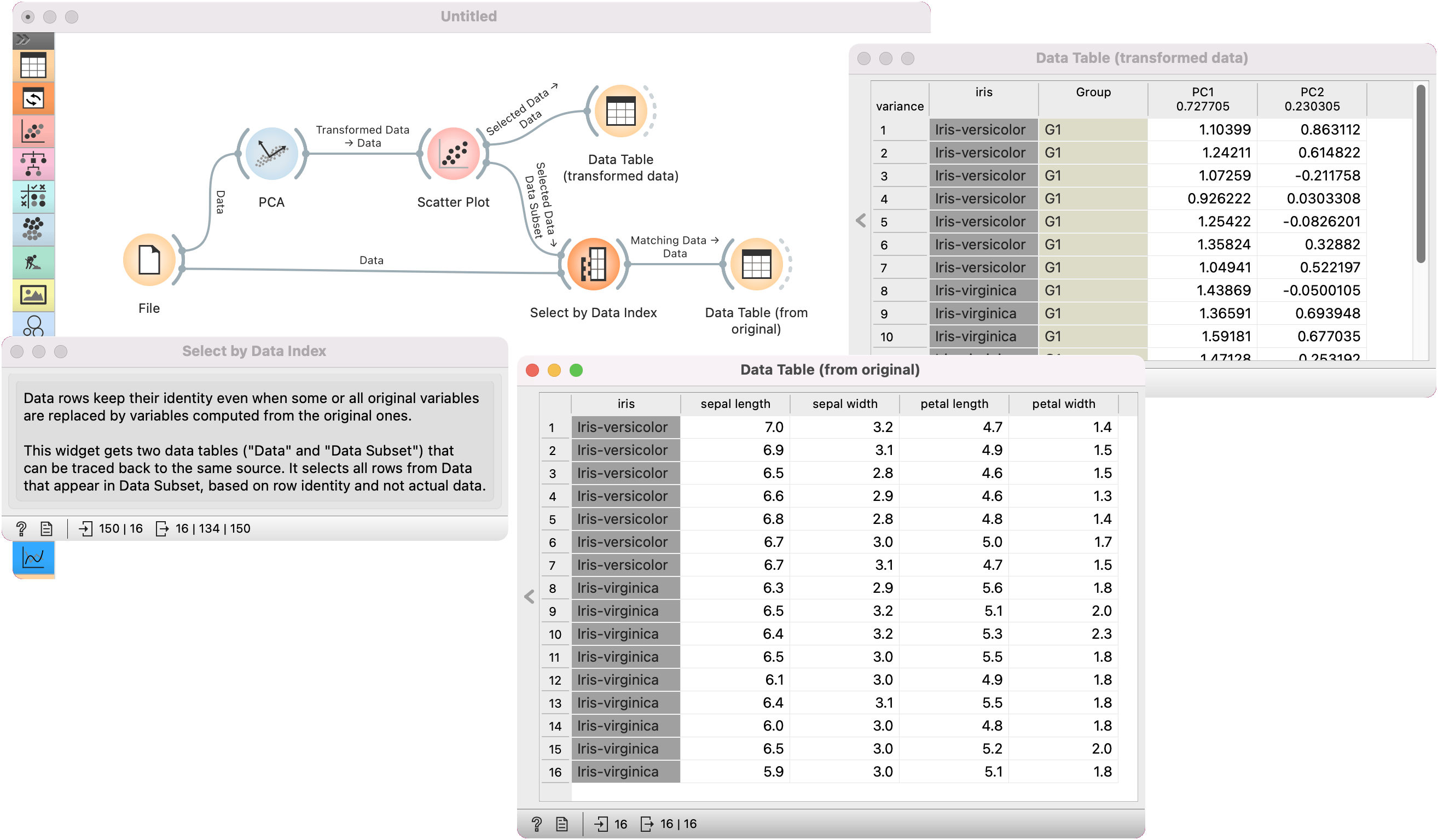
Select by Data Index enables matching the data by indices. Each row in a data set has an index and given a subset, this widget can match these indices to indices from the reference data. Most often it is used to retrieve the original data from the transformed data (say, from PCA space).

Example
A typical use of Select by Data Index is to retrieve the original data after a transformation. We will load iris.tab data in the File widget. Then we will transform this data with PCA. We can project the transformed data in a Scatter Plot, where we can only see PCA components and not the original features.
Now we will select an interesting subset (we could also select the entire data set). If we observe it in a Data Table, we can see that the data is transformed. If we would like to see this data with the original features, we will have to retrieve them with Select by Data Index.
Connect the original data and the subset from Scatter Plot to Select by Data Index. The widget will match the indices of the subset with the indices of the reference (original) data and output the matching reference data. A final inspection in another Data Table confirms the data on the output is from the original data space.