education
Ideas and Notes for Teachers
Blaž Zupan
Jun 16, 2022
On May 26, 2002, we had our first webinar targeting teaching with Orange. During the first part of the webinar, I demonstrated how we could use Orange to introduce classification trees. On their own, classification trees are quite lousy classifiers. They are, nevertheless, important as we can assemble them into very powerful classifiers. The lessons I have presented deal with overfitting and the idea that we should never report classification accuracy on the training data. The trick we use when teaching this is to show the trainees that classification trees also perform well on data with random, that is, useless labels (see the figure below). And then, of course, we ask the audience what went wrong and why and how we should fix the workflow.
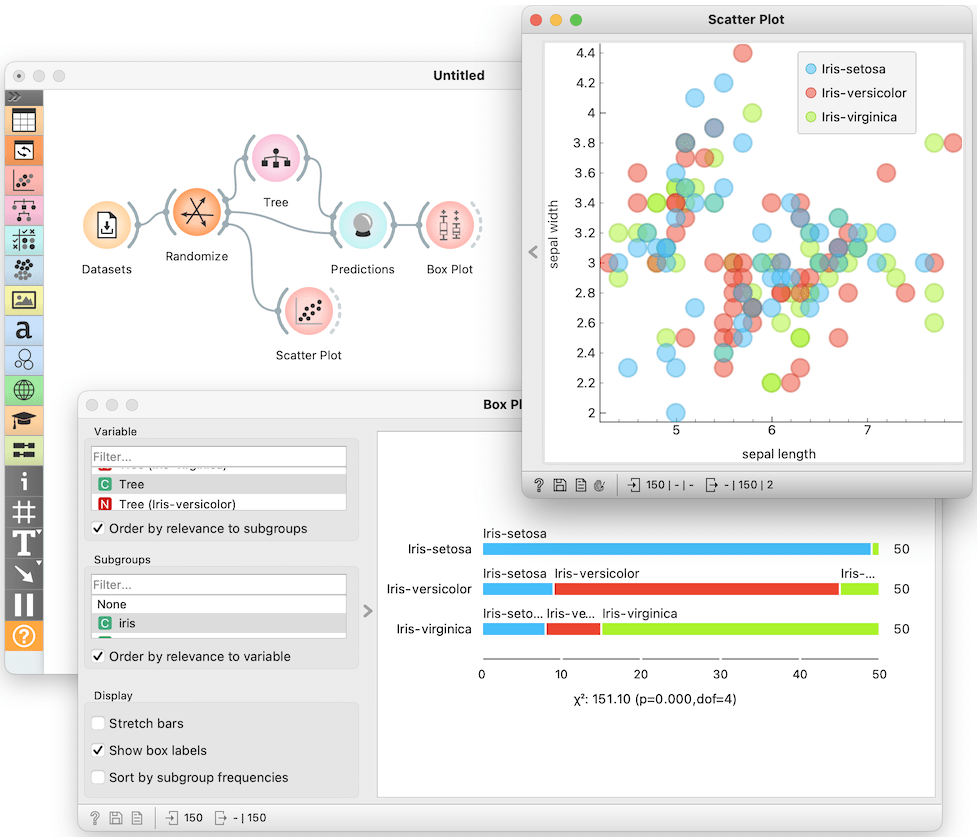
I presented this and several other lessons this week during the tutorial at Artificial Intelligence in Medicine conference. This year AIME took place in Halifax, and I am writing this blog on a plane to Brussels, where I will attend a kick-off meeting of an ARISA, a European project to devise certified lessons and training of AI for the EU industry. Training in AI is becoming a hot topic. :). Back to Halifax. I packed the presentation with a short showcase of lectures we usually use in training. The tutorial started at 14.00 with an introduction, and a complete showcase on image analytics, whereas the lessons I have presented included those from the following list. I am here showing the timing to appreciate what can one cover with Orange in a concise time:
- [15.00] Orange mechanics: data exploration on human development index data
- [15.10] Hierarchical clustering: data on grades in english and math
- [15.25] Cluster explanation: data on student grades, discussion on choosing the number of clusters
- [15.40] Clustering and geo maps: back to human development data, showcase of widgets in geo add-on
- [15.50] Outliers and inliers: silhouette score
- [15.55] K-means clustering on painted data
- [16.00] Introduction to classification tree: on Iris dataset, manual tree construction with widget that displays distributions
- [16.10] Overfitting: with classification trees on iris with randomized classes, accuracy estimate through random sampling, cross-validation
- [16.20] Regression: overfitting in training with polynomial expansion, introduction to regularization
- [16.30] Data projections: PCA, MDS and t-SNE on zoo dataset
- [16.40] single cell analytics, data projections
- [16.50] Image analytics, outlier detection, example with images of traffic signs
- [16.55] Gene expression analysis: dataset with single-cell gene expression analysis, classification, utility of gene markers, cell type discovery, discovery of new markers
During AIME, I also pointed out that the minimum time for training on different topics from above takes hours, not minutes. For example, here are some estimates of how long would a typical training block with Orange take:
- Data Exploration and Clustering: 3 hours
- Classification, evaluation of accuracy: 5 hours
- Regression, evaluation of accuracy: 5 hours
- Image analytics, including image clustering, classification, and regression: 3 hours
- Text Mining: 5 hours
- Gene expression analysis: 3 hours
During both events, the webinar and AIME tutorial, we presented the material that teachers, professors, and instructors can use in training. The material includes:
- Lecture notes, material in LaTeX, see also blog with examples of rendered notes
- YouTube videos
- our publications in training with Orange on outliers, gene expression analysis, and image analytics
You are most welcome to review and use the above material. We also welcome any suggestions and comments. Let us know about your ideas in the support channel on Discord.