analysis, dataloading, examples, features, orange3, release, text mining, version, widget, workshop
Text Analysis: New Features
AJDA
Aug 04, 2017
As always, we've been working hard to bring you new functionalities and improvements. Recently, we've released Orange version 3.4.5 and Orange3-Text version 0.2.5. We focused on the Text add-on since we are lately holding a lot of text mining workshops. The next one will be at Digital Humanities 2017 in Montreal, QC, Canada in a couple of days and we simply could not resist introducing some sexy new features_._
Related: Text Preprocessing
Related: Rehaul of Text Mining Add-On
First, Orange 3.4.5 offers better support for Text add-on. What do we mean by this? Now, every core Orange widget works with Text smoothly so you can mix-and-match the widgets as you like. Before, one could not pass the output of Select Columns (data table) to Preprocess Text (corpus), but now this is no longer a problem.

Of course, one still needs to keep in mind that Corpus is a sparse data format, which does not work with some widgets by design. For example, Manifold Learning supports only t-SNE projection.

Second, we've introduced two new widgets, which have been long overdue. One is Sentiment Analysis, which enables basic sentiment analysis of corpora. So far it works for English and uses two nltk-supported techniques - Liu Hu and Vader. Both techniques are lexicon-based. Liu Hu computes a single normalized score of sentiment in the text (negative score for negative sentiment, positive for positive, 0 is neutral), while Vader outputs scores for each category (positive, negative, neutral) and appends a total sentiment score called a compound.
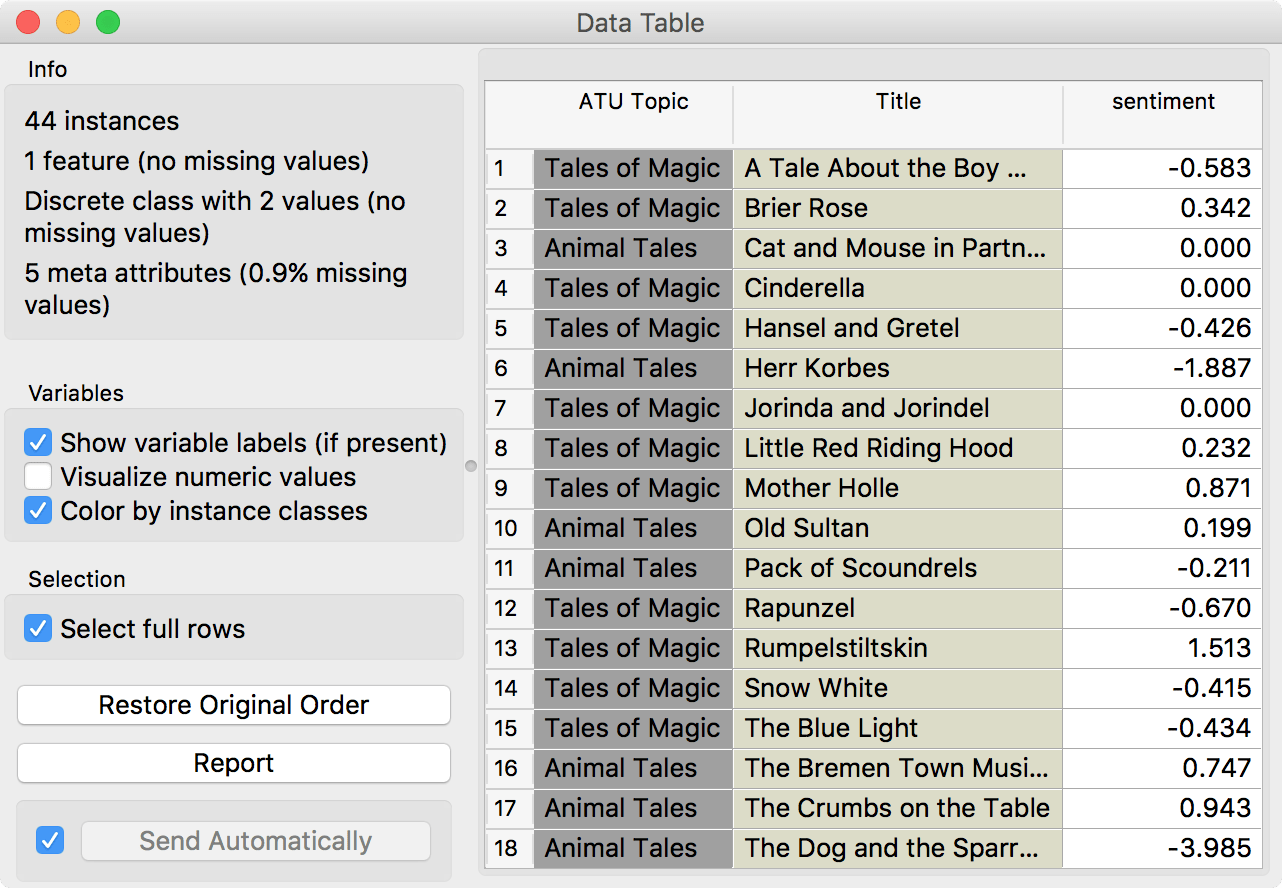
Liu Hu score.
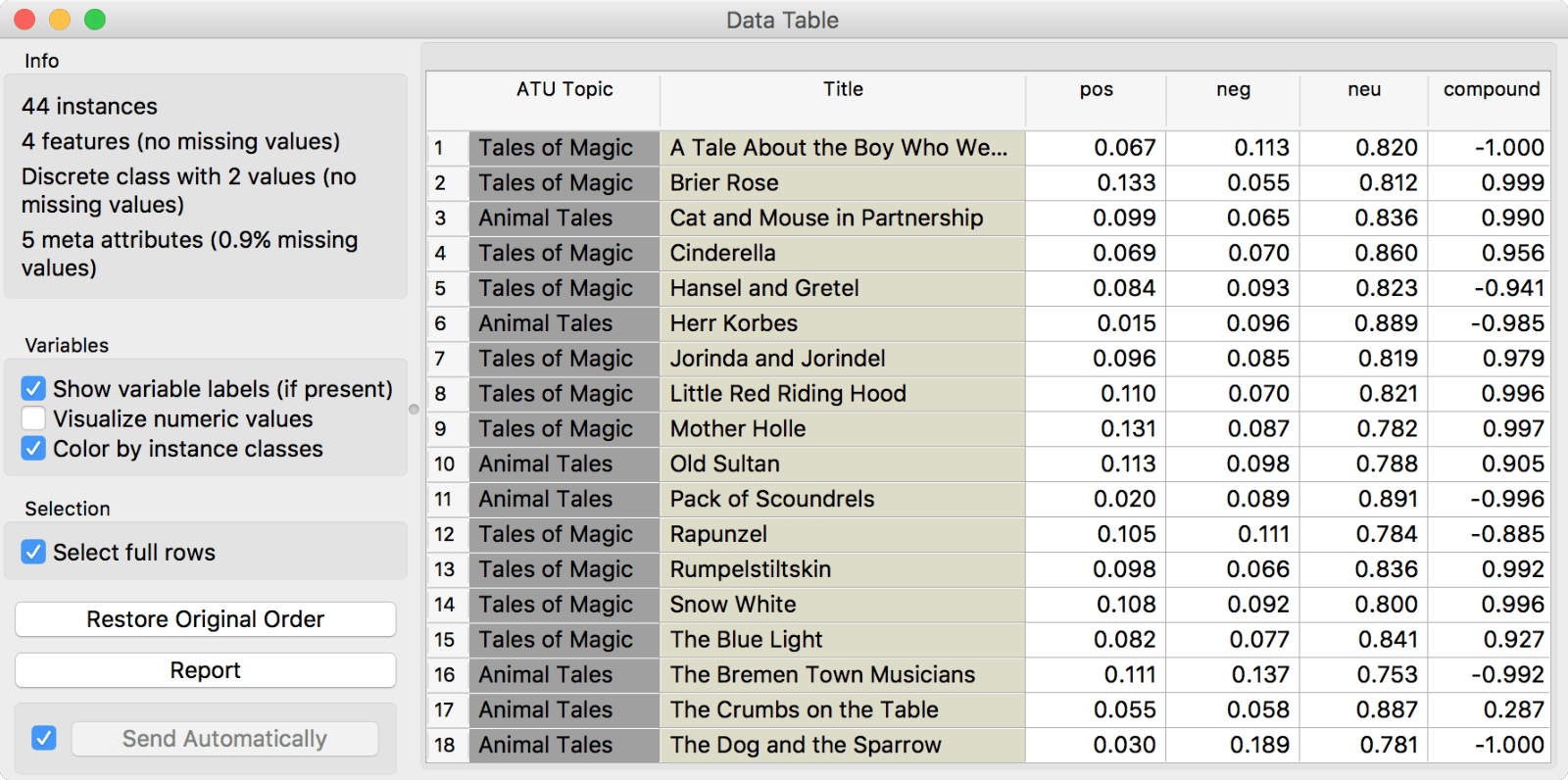
Vader scores.
Try it with Heat Map to visualize the scores.

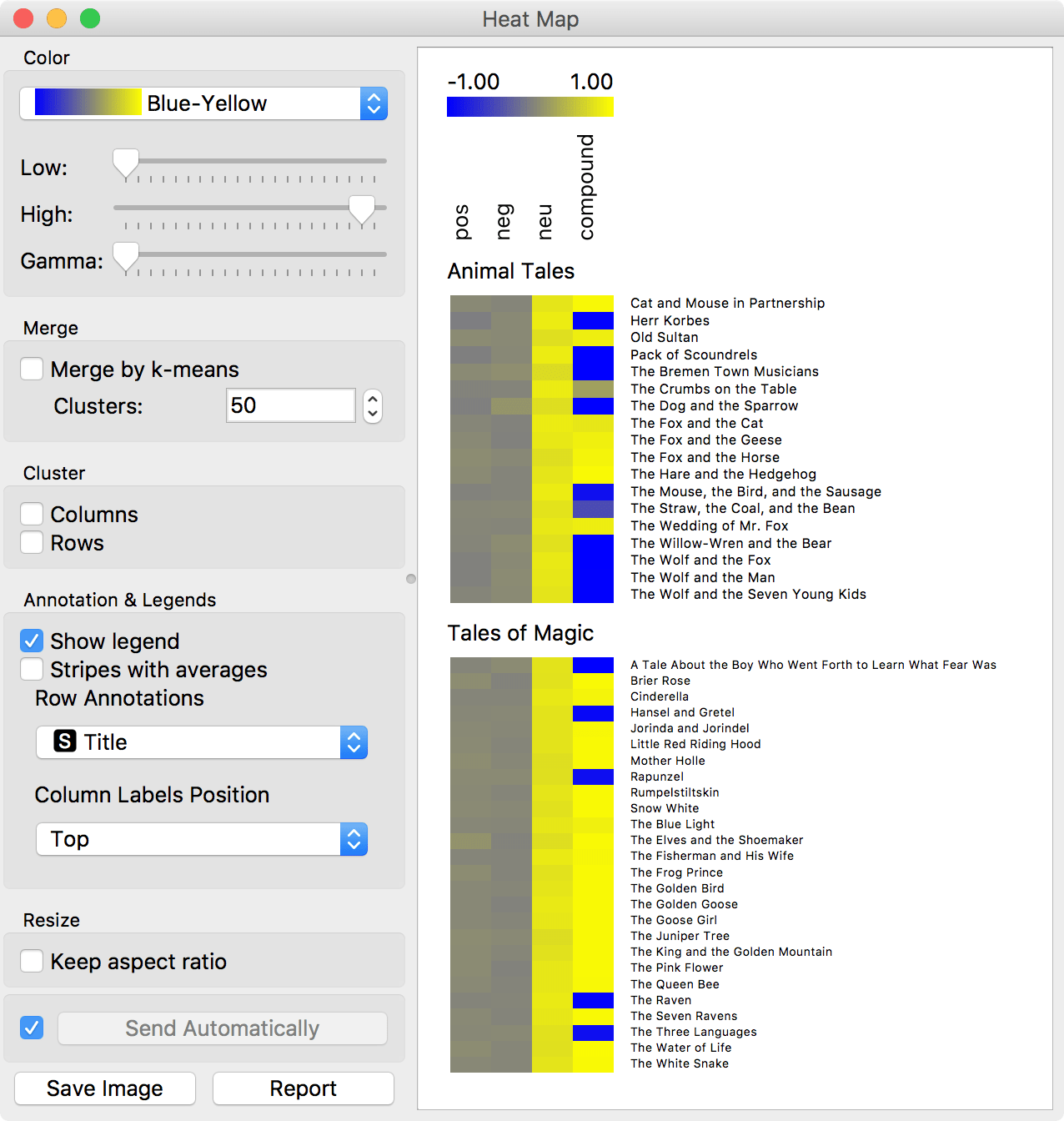
Yellow represent a high, positive score, while blue represent a low, negative score. Seems like Animal Tales are generally much more negative than Tales of Magic.
The second widget we've introduced is Import Documents. This widget enables you to import your own documents into Orange and outputs a corpus on which you can perform the analysis. The widget supports .txt, .docx, .odt, .pdf and .xml files and loads an entire folder. If the folder contains subfolders, they will be considered as class values. Here's an example.
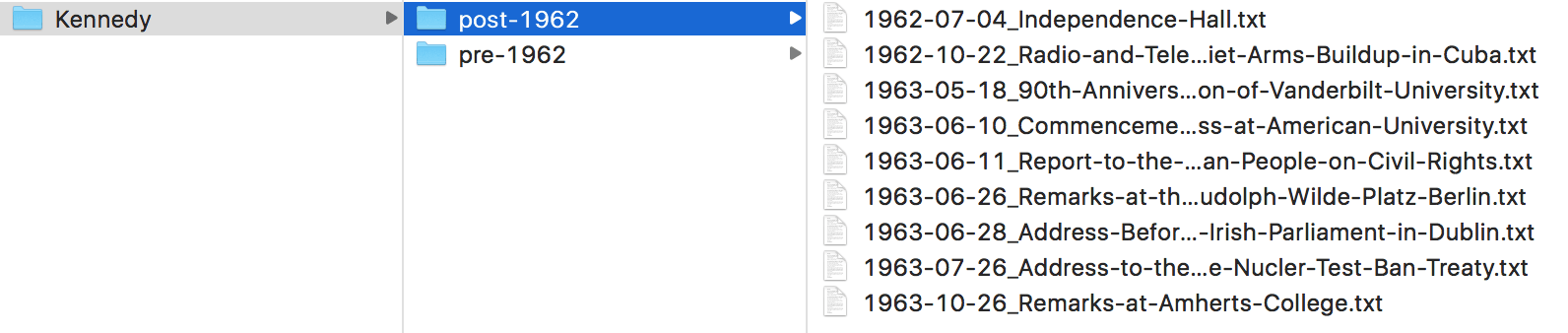
This is the structure of my Kennedy folder. I will load the folder with Import Documents. Observe, how Orange creates a class variable category with post-1962 and pre-1962 as class values.
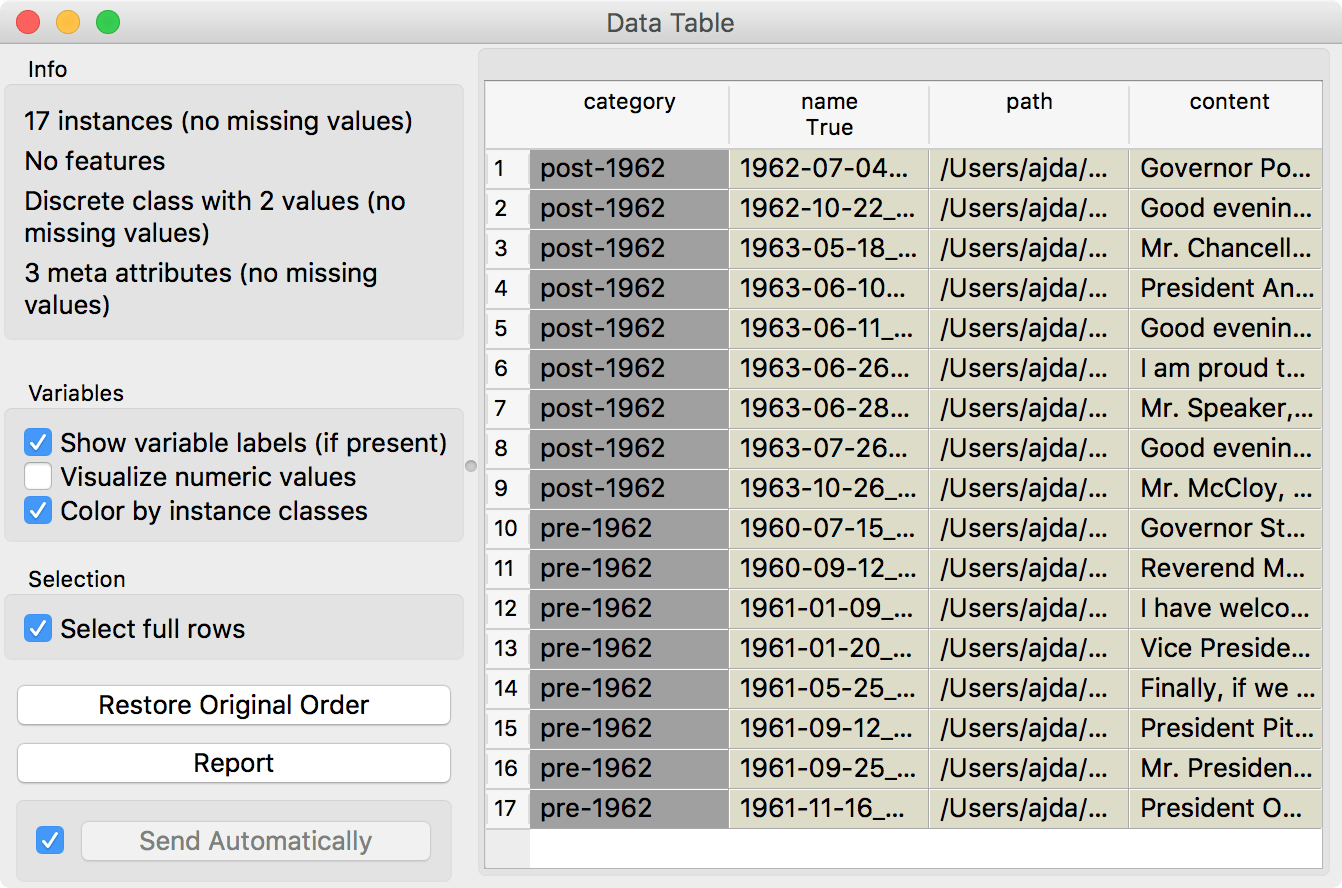
Subfolders are considered as class in the category column.
Now you can perform your analysis as usual.
Finally, some widgets have cool new updates. Topic Modelling, for example, colors words by their weights - positive weights are colored green and negative red. Coloring only works with LSI, since it's the only method that outputs both positive and negative weights.
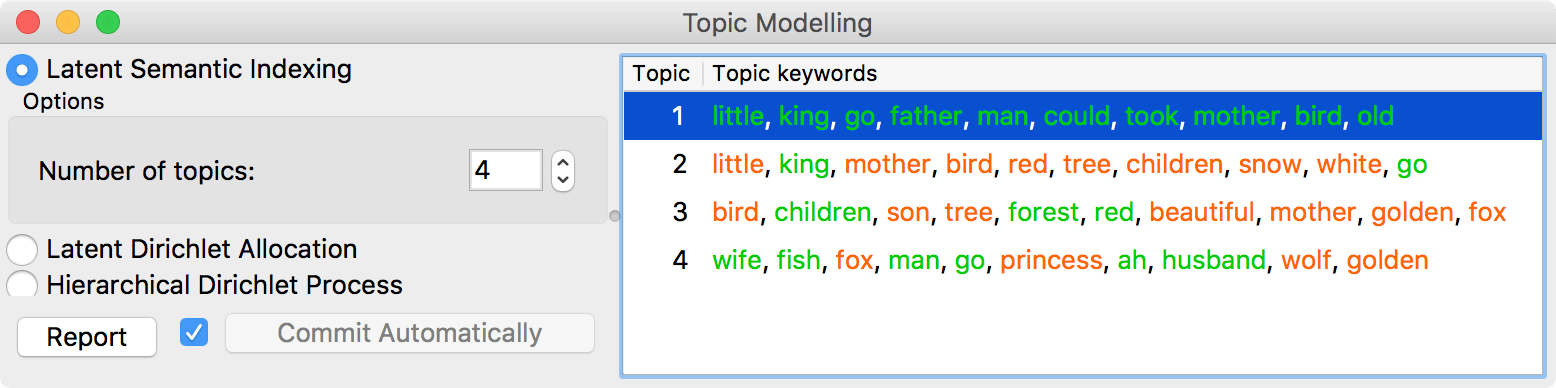
If there are many kings in the text and no birds, then the text belongs to Topic 2. If there are many children and no foxes, then it belongs to Topic 3.
Take some time, explore these improvements and let us know if you are happy with the changes! You can also submit new feature requests to our issue tracker.
Thank you for working with Orange! 🍊