orange3, preprocessing, text mining, visualization
Text Preprocessing
AJDA
Jun 19, 2017
In data mining, preprocessing is key. And in text mining, it is the key and the door. In other words, it's the most vital step in the analysis.
Related: Text Mining add-on
So what does preprocessing do? Let's have a look at an example. Place Corpus widget from Text add-on on the canvas. Open it and load Grimm-tales-selected. As always, first have a quick glance of the data in Corpus Viewer. This data set contains 44 selected Grimms' tales.
Now, let us see the most frequent words of this corpus in a Word Cloud.
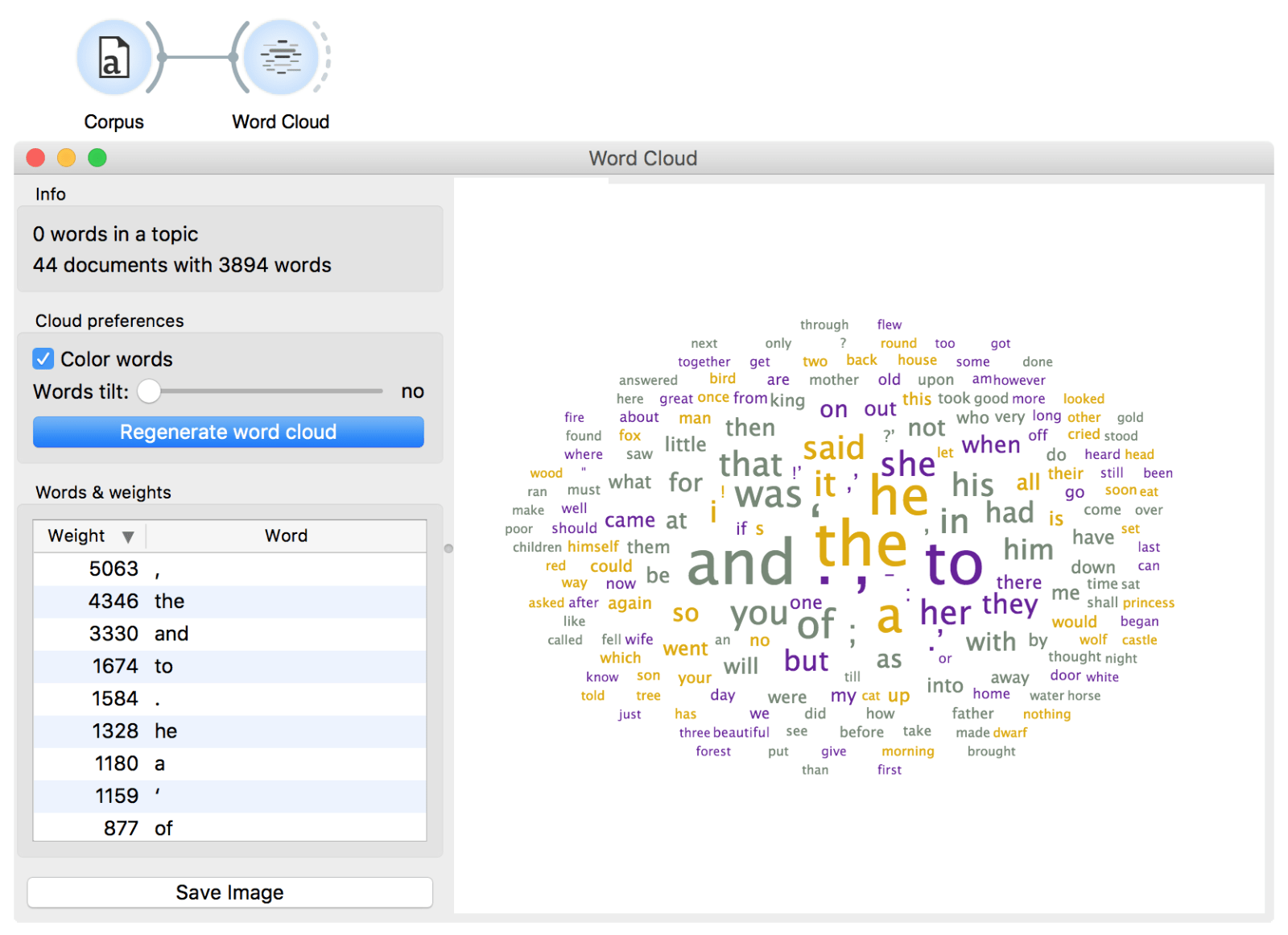
Ugh, what a mess! The most frequent words in these texts are conjunctions ('and', 'or') and prepositions ('in', 'of'), but so they are in almost every English text in the world. We need to remove these frequent and uninteresting words to get to the interesting part. We remove the punctuation by defining our tokens. Regexp \w+ will keep full words and omit everything else. Next, we filter out the uninteresting words with a list of stopwords. The list is pre-set by nltk package and contains frequently occurring conjunctions, prepositions, pronouns, adverbs and so on.
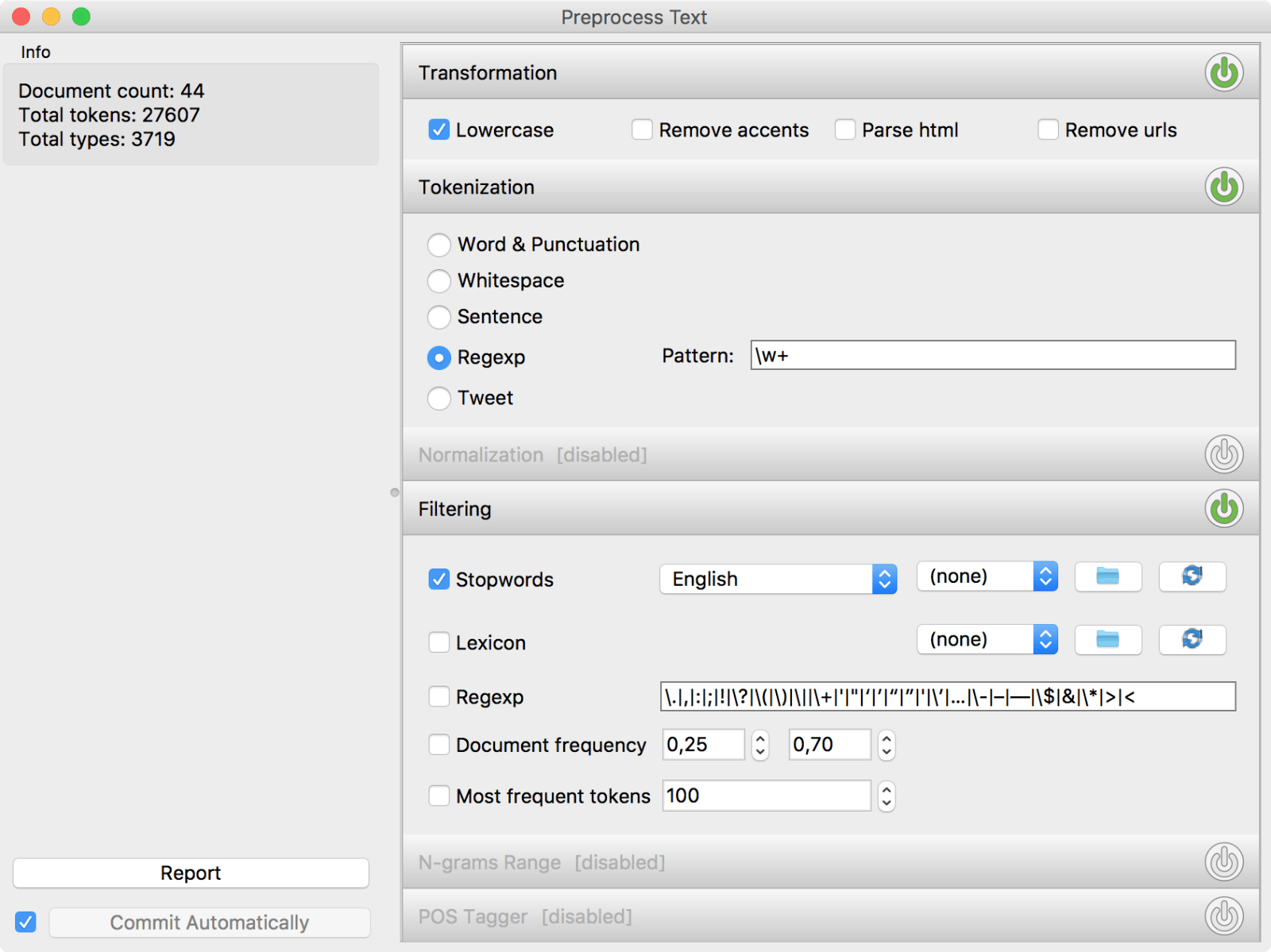
Ok, we did some essential preprocessing. Now let us observe the results.
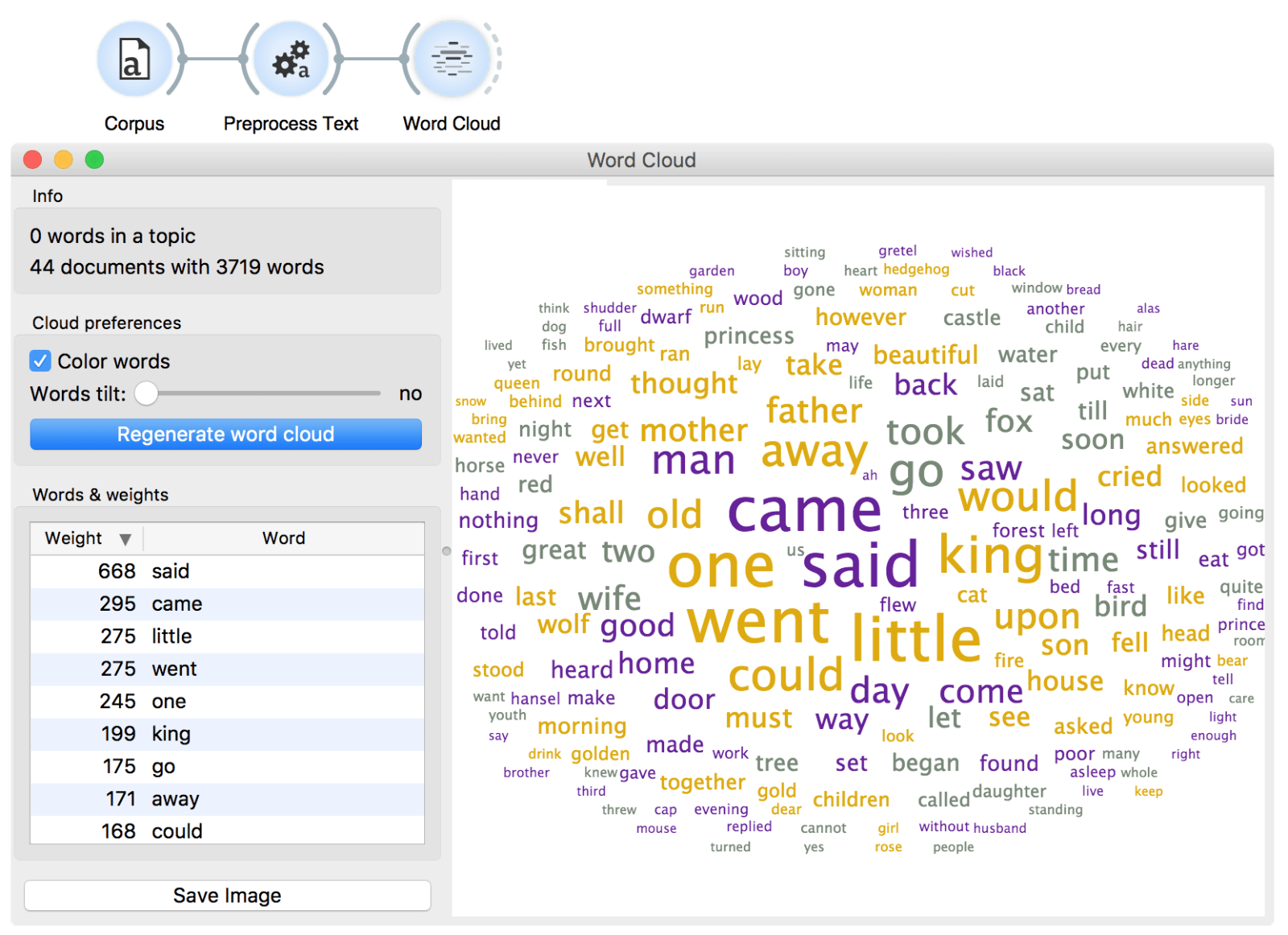
This does look much better than before! Still, we could be a bit more precise. How about removing the words could, would, should and perhaps even said, since it doesn't say much about the content of the tale? A custom list of stopwords would come in handy!
Open a plain text editor, such as Notepad++ or Sublime, and place each word you wish to filter on a separate line.
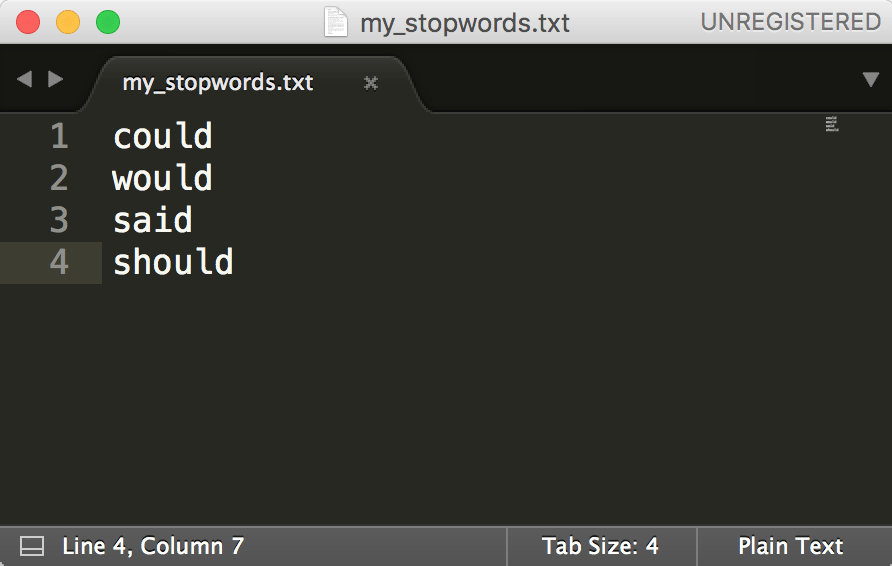
Save the file and load it next to the pre-set stopword list.

One final check in the Word Cloud should reveal we did a nice job preparing our data. We can now see the tales talk about kings, mothers, fathers, foxes and something that is little. Much more informative!