fairness, reweighing
Orange Fairness - Reweighing as a preprocessor
Žan Mervič
Sep 19, 2023
In the previous blog post, we introduced the Orange fairness Reweighing widget and used it to reweigh a dataset. In this blog, we will explore another use case for the Reweighing widget: using it as a preprocessor for a specific model.
Fairness metrics:
With the fairness addon and widgets that come with it, we also introduced four bias scoring metrics which we can use to evaluate the fairness of model predictions. The metrics are:
- Disparate Impact (DI): The ratio of favorable outcomes for an unprivileged group to that of the privileged group. An ideal value of 1.0 means the ratio is the same for both groups.
- DI < 1.0: The privileged group receives favorable outcomes at a higher rate than the unprivileged group.
- DI > 1.0: The privileged group receives favorable outcomes at a lower rate than the unprivileged group.
- Statistical Parity Difference (SPD): The difference in favorable outcomes. An ideal value is 0.0.
- SPD < 0: The privileged group has a higher rate of favorable outcomes.
- SPD > 0: The privileged group has a lower rate of favorable outcomes.
- Average Odds Difference (AOD): This metric calculates the average difference between the true positive rates (correctly predicting a positive outcome) and false positive rates (incorrectly predicting a positive outcome) for both the privileged and unprivileged groups. A value of 0.0 indicates equal rates for both groups, signifying fairness.
- AOD < 0: Indicates bias in favor of the privileged group.
- AOD > 0: Indicates bias against the privileged group.
- Equal Opportunity Difference (EOD): The difference in true positive rates. An ideal value is 0.0, indicating the difference in true positive rates is the same for both groups.
- EOD < 0: The privileged group has a higher true positive rate.
- EOD > 0: The privileged group has a lower true positive rate.
Weighted Logistic Regression and Combine Preprocessors:
At the time of writing, there were two limitations in using the Reweighing widget as a preprocessor:
- Currently, model widgets in Orange do not account for instance weights when training.
- Model widgets only accept one preprocessor widget as an input; this usually would be fine since all preprocessors can be added from a single widget called Preprocess, but Reweighing is a separate widget and thus could not be combined with other methods.
To combat this, we introduced two new widgets which we will use in the example below:
- Weighted Logistic Regression is an adapted form of the Logistic Regression widget designed to handle weighted datasets.
- Combine Preprocessors, which enables users to merge multiple preprocessors into one before inputting it into a widget. This becomes handy when integrating preprocessors other than Reweighing with a model.
Orange use case
Now that we know all the required widgets and new fairness scoring metrics, let us explore a real-world example of using the reweighing widget as a preprocessor. Doing so will allow us to use the reweighing algorithm when evaluating model performance using cross-validation, random sampling, etc.
We will use the German credit dataset for this illustration. The German Credit is a dataset related to bank loans. The main goal is to assess an individual's credit risk - whether a person is a good or bad credit risk. The collection consists of 1,000 cases with 20 attributes, of which 13 are categorical and 7 are numerical. The attributes include financial characteristics such as the amount and purpose of the loan, employment status, and credit history, as well as personal features like age, gender, housing status, and foreign worker status. The most frequently used protected attributes in this collection are gender and age.
Like the previous blog, we will not use the As Fairness Data widget to select fairness attributes. Instead, we will use the default attributes, "sex" as the protected attribute and "male" as the privileged group, already defined in the dataset.
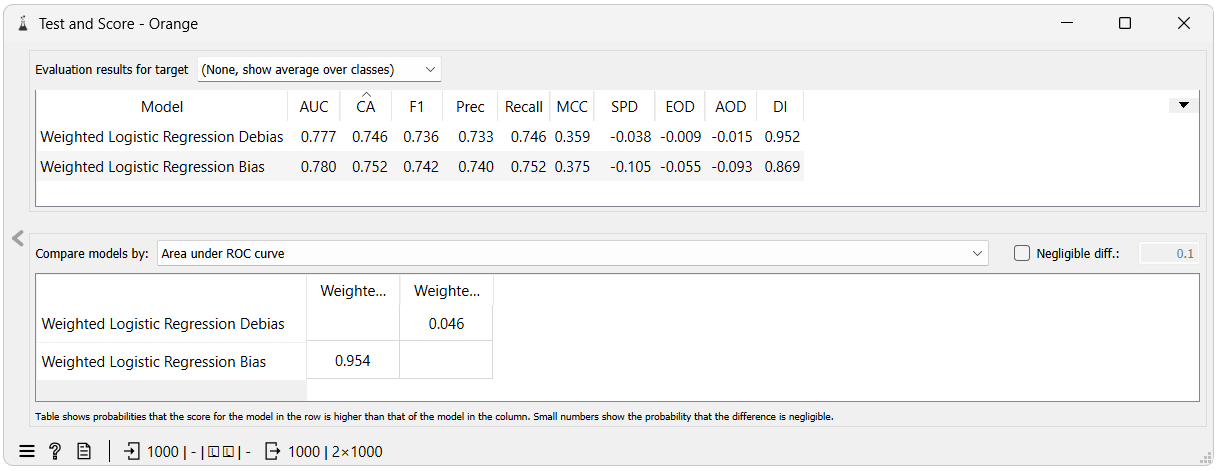
The results show that the model using reweighing as a preprocessor achieved better fairness scores than the model without reweighing at the cost of slightly lower accuracy.
In this case DI metric went from 0.869 to 0.952, SPD went from -0.105 to -0.038, EOD went from -0.055 to -0.009 and AOD went from -0.093 to -0.015. All metrics indicate less bias towards the unprivileged group.
We can easily visualize the Disparate Impact metric using a box plot. For a clearer visualization, we have used the Edit Domain widget to merge all values of each protected group into one, which resulted in two groups: males and females.

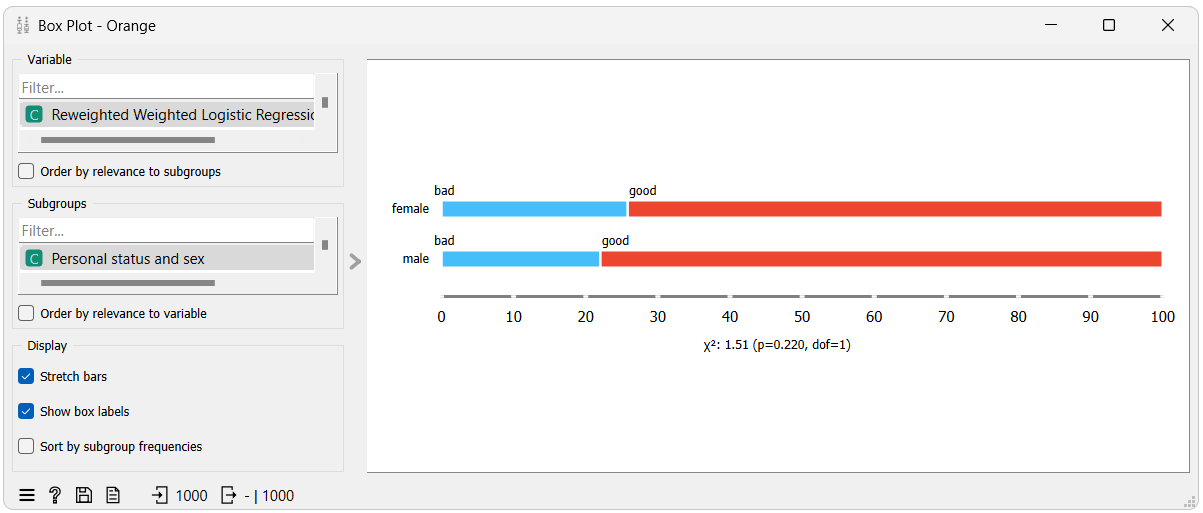
The first box plot shows the ratio of favorable and unfavorable outcomes for the unprivileged and privileged groups (DI) from the model without reweighing. The second box plot shows the same for the model with reweighing.
We can see that when using reweighing the amount of favorable outcomes increased for the unprivileged group and decreased for the privileged group bringing the ratios closer between the two groups.