data
How to get data from Wikidata?
Janez Demšar
Apr 20, 2025
Pumice is a project in which we create school lesson plans for teaching data mining. Our good ideas are often impeded by the lack of data sets: you want to do something about cars, but you don't have a suitable ready-made data on UCI, Kaggle or anywhere else.
Wikipedia is a great source of information, but not of data. Machine-readable data, that is. For that, we need to turn to Wikidata, the sister project of Wikipedia.
Fičo
Fičo (pronounced like "feecho") is a nickname for a small car, officially called Zastava 750. It's a version of Fiat 600, produced in the former Yugoslavia. This was one of the (more or less) two cars I'd see in my childhood.

Open the Wikipedia page for Zastava 750. Not just for curiosity. See the "Tools" menu on the top right? Open and select "Wikidata item". This will open the Wikidata page for Zastava 750. Scroll through it.
Q148237 is the entity ID representing the Zastava 750. Among the relationships, it says, for example, that Q148237 is an "instance of" Q3231690, where Q3231690 is "automobile model." In other words, it says that the Zastava 750 is a car. It also says that its weight is 605 kg, it is "followed by" Q21205906, which is the Yugo, 923,847 of them were made, and so on.
All of this is incredibly interesting, and we can gather it in the form of JSON ... but for our use, we will need data about multiple things of the same kind, for example, multiple cars. We can access the database from which this page is built through SPARQL.
You know how to write SPARQL queries? Me neither. This is a query language for graphs. This is where ChatGPT comes in.
You should never ask large language models to provide data (at least not at the time of writing this blog). But you can ask it to help you get the data:
Can you construct a wikidata query for car
images that would give me a picture, model name,
manufacturer and state, and the year the car was
produced?
It answered:
Sure! Here is a SPARQL query for Wikidata that
retrieves images of cars along with their model
name, manufacturer, production start year, and
country of origin (state). You can run this query
using the [Wikidata Query Service].
SELECT ?car ?carLabel ?image ?manufacturerLabel ?countryLabel ?startYear WHERE {
?car wdt:P31 wd:Q3231690; # Instance of automobile model
wdt:P18 ?image; # Image
wdt:P176 ?manufacturer; # Manufacturer
wdt:P571 ?inception. # Inception (start year)
OPTIONAL {
?manufacturer wdt:P17 ?country. # Manufacturer's country of origin
}
BIND(YEAR(?inception) AS ?startYear)
FILTER(?startYear >= 1920) # Filter cars produced from 1920 onwards
SERVICE wikibase:label {
bd:serviceParam wikibase:language "en".
}
}
ORDER BY ?startYear
LIMIT 100
We then open the link to the Wikidata Query Service, https://query.wikidata.org/, and paste the query above into it. In response, we get a table that starts like this:
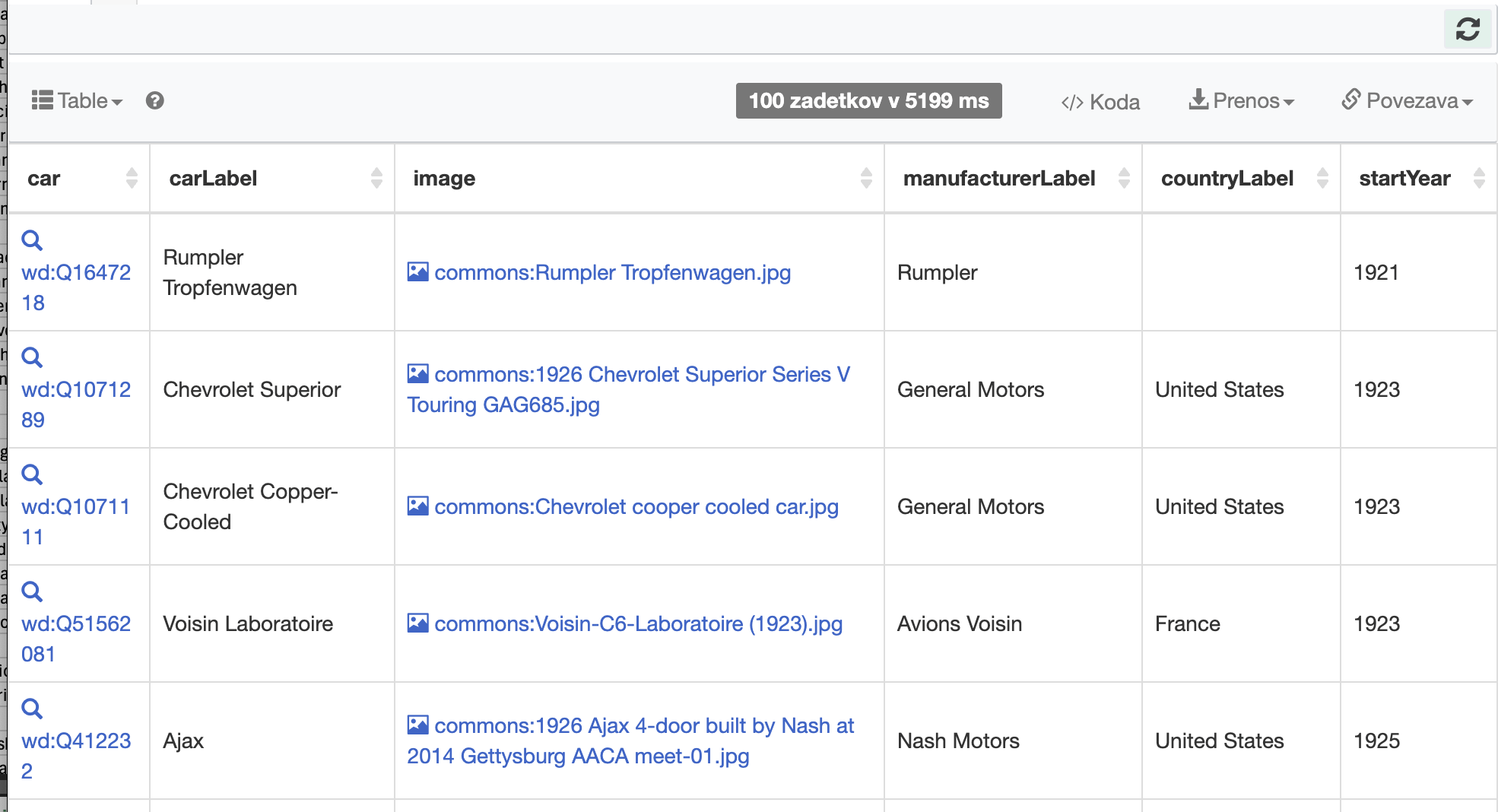
If we like it, we can delete LIMIT 100 (or leave it as is), and we’ll get all the results.
Then, under Download, we can choose JSON or TSV or whatever format we prefer, and we’ll get the table. CSV, for example, will look like this:
car,carLabel,image,manufacturerLabel,countryLabel,startYear
http://www.wikidata.org/entity/Q1647218,Rumpler Tropfenwagen,http://commons.wikimedia.org/wiki/Special:FilePath/Rumpler%20Tropfenwagen.jpg,Rumpler,,1921
http://www.wikidata.org/entity/Q1071289,Chevrolet Superior,http://commons.wikimedia.org/wiki/Special:FilePath/1926%20Chevrolet%20Superior%20Series%20V%20Touring%20GAG685.jpg,General Motors,United States,1923
http://www.wikidata.org/entity/Q1071111,Chevrolet Copper-Cooled,http://commons.wikimedia.org/wiki/Special:FilePath/Chevrolet%20cooper%20cooled%20car.jpg,General Motors,United States,1923
http://www.wikidata.org/entity/Q51562081,Voisin Laboratoire,http://commons.wikimedia.org/wiki/Special:FilePath/Voisin-C6-Laboratoire%20%281923%29.jpg,Avions Voisin,France,1923
http://www.wikidata.org/entity/Q412232,Ajax,http://commons.wikimedia.org/wiki/Special:FilePath/1926%20Ajax%204-door%20built%20by%20Nash%20at%202014%20Gettysburg%20AACA%20meet-01.jpg,Nash Motors,United States,1925
This was an example with cars. Sometimes, the table from Wikidata will be enough for us — we’ll just make a few minor adjustments, import it into Orange (or wherever else), and use it.
Other times, we’ll need to process it further, for example in Python. Would you like to grab all these images from the web? You know how to write a script for it... if not, chatGPT is perfectly suited for such tasks as a programmer.
Sitcoms
I haven't done anything useful with the data about cars yet, but here's an example of a dataset I created for a lesson plan: it's a school activity about recommender systems. I had a version for children, which was about cartoons, and we wanted one with sitcoms that we can use with older kids and for training teachers.
For this I used just ChatGPT, not Wikidata.
Give me a list of sixty popular sitcoms as
a Python list containing links to IMDB.
The point here is that I requested the list in Python format: this made it easier to continue. I got this:
sitcoms = [
{"title": "Friends",
"imdb_link": "https://www.imdb.com/title/tt0108778/"},
{"title": "Seinfeld",
"imdb_link": "https://www.imdb.com/title/tt0098904/"},
{"title": "The Office (US)",
"imdb_link": "https://www.imdb.com/title/tt0386676/"},
{"title": "Parks and Recreation",
"imdb_link": "https://www.imdb.com/title/tt1266020/"},
Here, one must be cautious. Among the links ChatGPT provided, three or four were incorrect — they pointed to completely different series. ChatGPT is not a reliable data source, but here it was easy to catch its mistakes in the next step.
For the educational activity I was preparing, I wanted posters of those series. When I asked:
What's the easiest way to download poster images?
I want to do it programmatically.
It told me about the Open Movie Database (https://www.omdbapi.com/). It has an API that requires your email to which it sends you a key, with which you can make up to 1000 requests per day.
Given an IMDb tt code, and assuming my
apikey is 12345, how do I download from
omdb using Python and urllib.request?
It gave me this:
import urllib.request
import json
# Define your API key and IMDb tt code
api_key = "12345"
tt_code = "tt0111161" # Example IMDb code for The Shawshank Redemption
# Construct the URL for the OMDb API
url = f"http://www.omdbapi.com/?apikey={api_key}&i={tt_code}"
try:
# Make the request
with urllib.request.urlopen(url) as response:
# Read and decode the response
data = response.read().decode("utf-8")
# Parse the JSON
movie_data = json.loads(data)
# Output the result
print(movie_data)
except Exception as e:
print("An error occurred:", e)
And that was it. :)