text mining, sentiment analysis, corpus, story arc, heat map, line chart
Detecting Story Arcs with Orange
Ajda Pretnar
Jul 27, 2020
Reading is fun because it takes you on a journey. Mostly, it is a journey of emotions as you live and breathe with the protagonist and her adventures. Today, we will have a look at how to detect sentiment in a story, plot story arcs and analyze the content of the key segments in a corpus.
Related: Text Workshops in Ljubljana
We will be using a corpus of Anderson's tales, which is available in the Corpus widget (data set anderson.tab). Load it in the widget. Next, we will select a single tale which we will analyze, say, Little Match Seller. Connect Corpus to Data Table and select the tale. We all know the story of a little girl selling matches on a New Year's Eve and freezing to death. It is one of the saddest stories ever told. One could almost forget there are positive parts, such as the girl's visions in the moments before her death, which show a glimmer of hope, the only consolation the girl had in her life. Let us verify this in Orange.
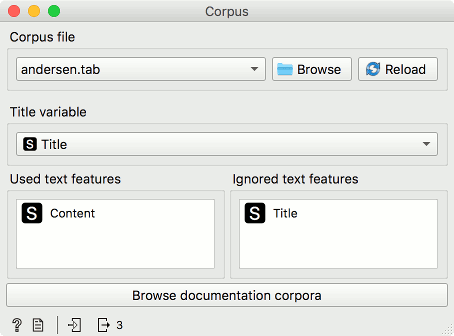
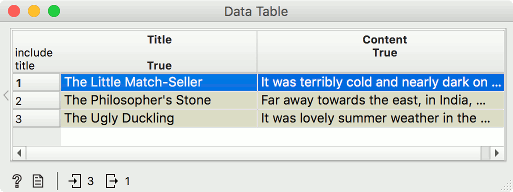
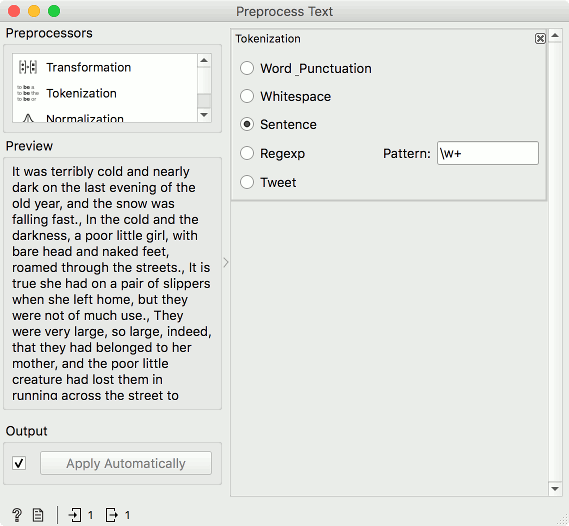
With our story selected, we have to split it into sentences. At the moment, our story is a single row in the data, but we wish to have each sentence in its own row. We will use Preprocess Text and select Sentence tokenization. I have removed the redundant preprocessors and kept the only one we need.
Some Python magic will help us create a new corpus from the existing tokens (sentences). Copy and paste the script below into the Python Script widget. Do not forget to press Run once you have pasted the script into the widget.
import numpy as np
from Orange.data import Domain, StringVariable
from orangecontrib.text.corpus import Corpus
tokens = in_data.tokens
new_domain = Domain(attributes=[], metas=[StringVariable('Sentences'), StringVariable('Title')])
titles = []
content = []
for i, doc in enumerate(tokens):
for t in doc:
titles.append(in_data[i]['Title'].value)
content.append(t)
metas = np.column_stack((content, titles))
out_data = Corpus.from_numpy(domain=new_domain, X=np.empty((len(content), 0)),
metas=metas)
out_data.set_text_features([StringVariable('Sentences')])

Perfect, our data is now ready for the final step. Add another Preprocess Text and keep the default preprocessors. They will lowercase our sentences, split by words and remove English stopwords.
Finally, add the Sentiment Analysis widget. By default, the widget uses the Vader algorithm, which works quite well for English. Please note that it won't work for other languages, as all of Orange's sentiment models are language specific. You can use Multilingual sentiment for non-English texts.

At last, it is time to analyze the data. We will use Timeseries add-on to plot sequential data. First, we will pass the data to the As Timeseries widget and set the Sequence implied by the instance order option. This tells Orange that our data is already ordered by time - in our case, by the order in which each sentence appears in the story.
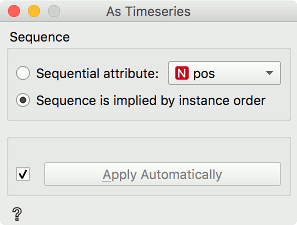
Connect Line Chart to As Timeseries. In the widget, select Compound variable, which shows the total sentiment of each sentence. The peaks represent the parts of the story with positive emotions and the drops the parts with the negative ones.

To explore the data in depth, connect Heat Map to Sentiment Analysis. Heat Map will show all 4 sentiment attributes, namely positive (pos), negative (neg), neutral (neu) and compound sentiment. But our data is all over the place. Let us order it. Select Clustering (opt. ordering) under the Clustering - Rows option. This will cluster the sentences by their similarity, specifically by how similar their emotion is.
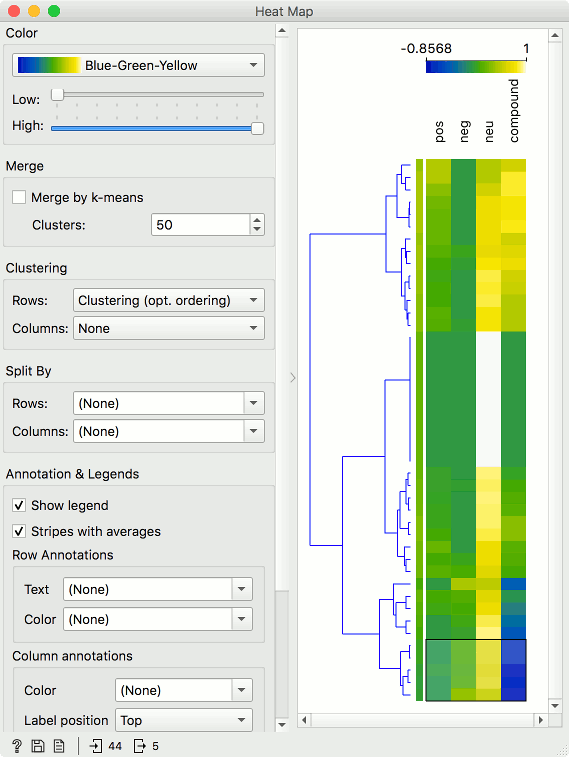
Great! Now this looks like something useful. The blue sections represent the negative sentences, while the yellow and white sections represent the positive ones. Let us select the cluster with negative sentences and observe it in a Corpus Viewer.
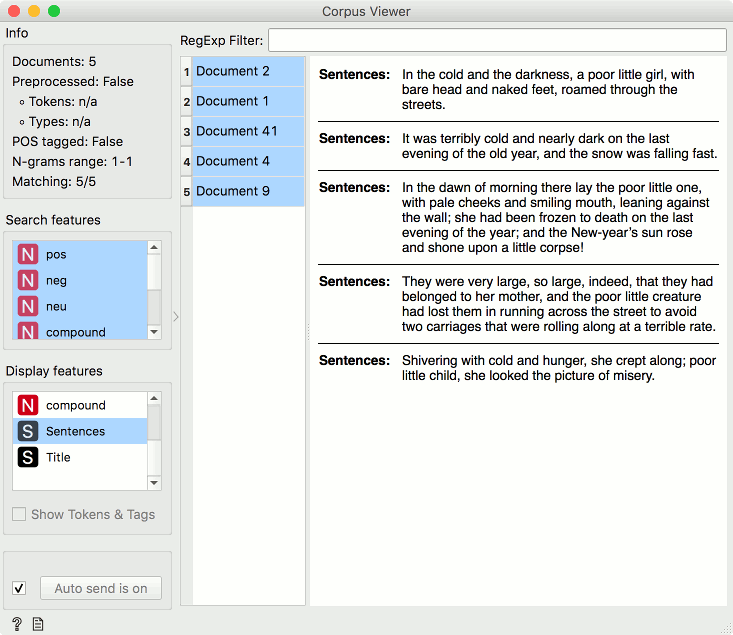
I have set Sentences as the single Display variable and selected all the sentences to show them in a list. Unsurprisingly, here is the last sentence of the story, in which a girl if found dead in the street on a New Year's Day.
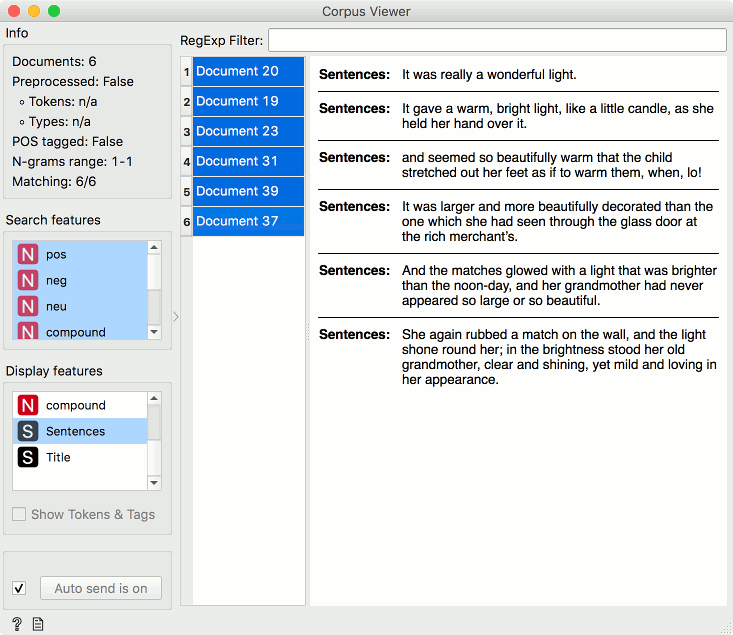
To finish, let us explore the positive sentences, too. Select the positive section in the Heat Map and observe it in a Corpus Viewer. Now rethink the story, reread her visions in the last moments of her life and how happy she was when she died. Couldn't we say that ... the story has a happy ending?
While the workflow is quite long, it is conceptually very simple. This is a quick and easy way to explore the story arcs and sentiment in a text. We imagine this to be a very useful tool for the teachers who wish to experiment a bit in their language classes and offer a fun and fruitful way of exploring literature.
