text mining, images
Cookie Mining
Blaž Zupan
Dec 22, 2023
We just released a video about cookie mining. Yes, mining data from cookies. The video goes through the technicalities rather quickly and deliberately doesn't dive into the intricacies of Orange - it's Christmas time and we're focusing on cookies. To accompany the video, here is a blog that dives into the workflow we used and explains its inner workings.
To replicate our cookie mining, you will need:
- Orange, :)
- Orange's Text, Image Analytics, and Prototypes add-ons installed (currently, ChatGPT widgets are in the Prototypes add-on),
- the cookie data file with a list of cookie names,
- the images of cookies,
- OpenAI's API key to the ChatGPT. Alternatively, you can start with the data file which already contains cookie descriptions and bypass the use of the ChatGPT Constructor widget.
Here is the workflow we constructed in the video:
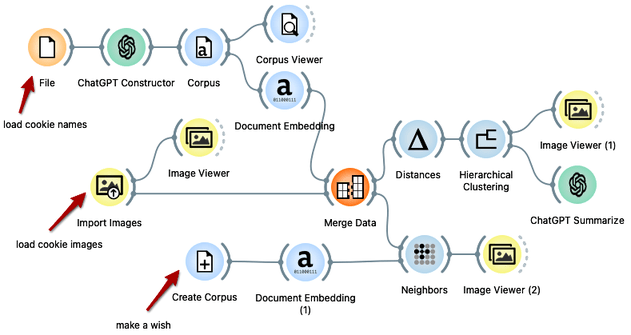
The workflow consist of three mail branches.
1. Cookie Description Embedding and Clustering
In the top branch, which starts with a File widget, we load the cookie names from the Excel file and pass them to the ChatGPT Constructor. This takes the cookie name, one line at a time, and constructs a ChatGPT prompt, where the start of the prompt is the text we entered in the ChatGPT Constructor, followed by the cookie name attribute from the data file. The output of ChatGPT Constructor is then a data table with an extra row containing cookie descriptions.Here is the workflow and widgets that illustrate this part of our cookie analysis pipeline.

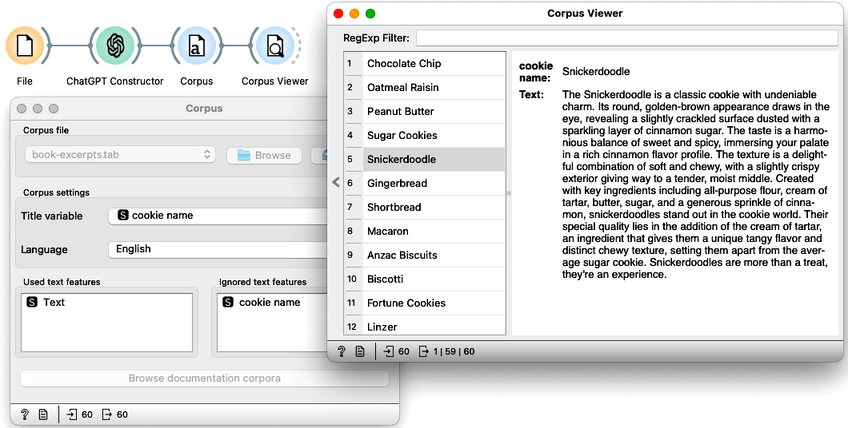
Some cookie descriptions are long, and we can read them more easily in the Corpus Viewer. To use it, we need to mark that our data table contains the text corpus and specify that the text we want to mine is stored in the "Text" attribute, i.e. the attribute constructed by the ChatGPT Constructor.
We pass the corpus data to the Document Embedding widget, where we use BERT sentence embedding to describe each cookie description with its embedding, i.e. with a numeric vector. Then we use the Data Table widget to check the result of the embedding.

Note that while we set the ChatGPT temperature parameter to 0, which tells ChatGPT to always choose the most likely word when constructing a text sequence, ChatGPT would still randomly choose the best continuation among the top-ranked equally likely words. Since we cannot control the random seeds in ChatGPT, this means that you may get slightly different cookie descriptions than ours, and there is no way to exactly replicate our results.
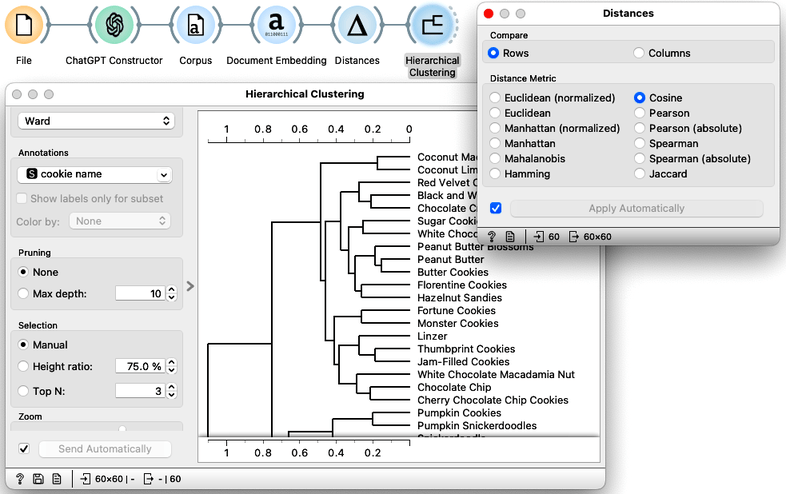
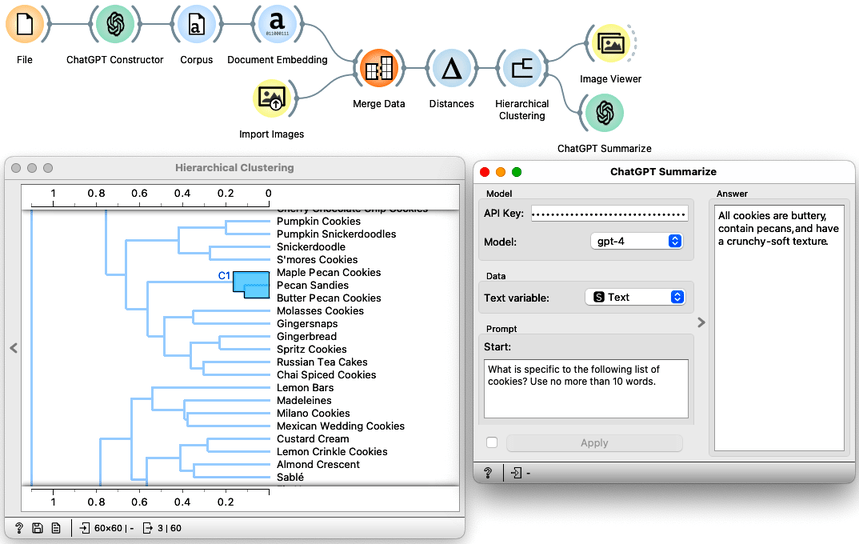
We feed the cookie embedding into the hierarchical clustering pipeline, which must first estimate the pairwise cookie distances and then feed the distances into the Hierarchical Clustering widget. We used cosine distance and Ward linkage.
If you are like me, cookie names alone would not tell you much. We need cookie images! Our goal is to be able to select a cookie cluster and see what those cookies actually look like.
2. Cluster Exploration with Images
We have prepared a folder with images of our cookies and conveniently named the files with the cookie names.
We can load the cookie images into Orange with the Import Images widget and check the loaded data with the Image Viewer widget.
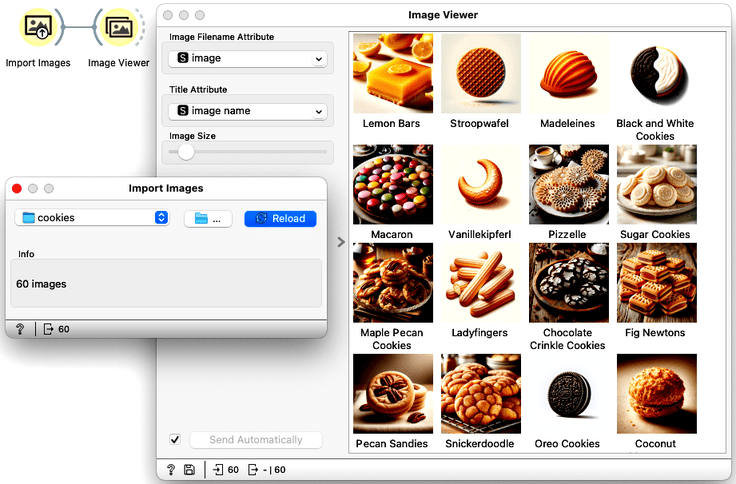
They all look great! Cookies, I mean :). Note that Orange does not carry images with the data at all, but instead constructs the data table when using Import Images, which stores the location of image files in one of the fields. These locations are then used by the image viewer when displaying images. We can also check if this is indeed the case by observing the data passed by the Import Images widget, as I have done below.
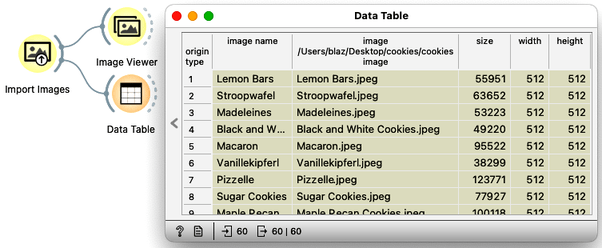
We are now ready to merge the text data with the image data. We will do this after the text embedding and tell the Merge Data widget to match the rows of the two files using the cookie name attribute from the text record and the image name attribute from the image record.
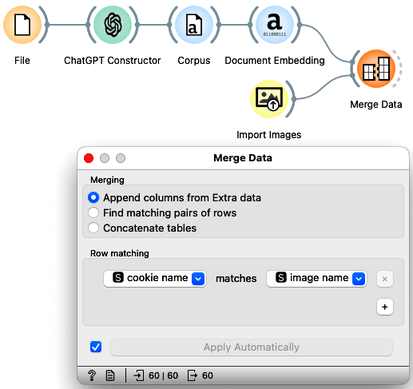
Now, with the merged dataset, we can do the clustering and observe the images of the cookie groups. We can also try to summarize the descriptions of the cookies selected in the dendrogram.
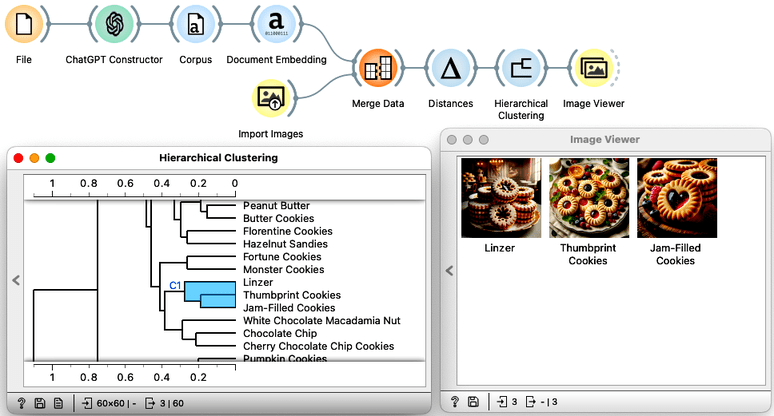
Oh, joy! A visual browser of the cookie world!
As a final touch, we can ask the ChatGPT Summarize widget to construct a summary from all the descriptions of the cookies we selected in the hierarchical clustering dendrogram.
3. Cookie Wish and Nearest Neighbors in the Cookie Vector Space
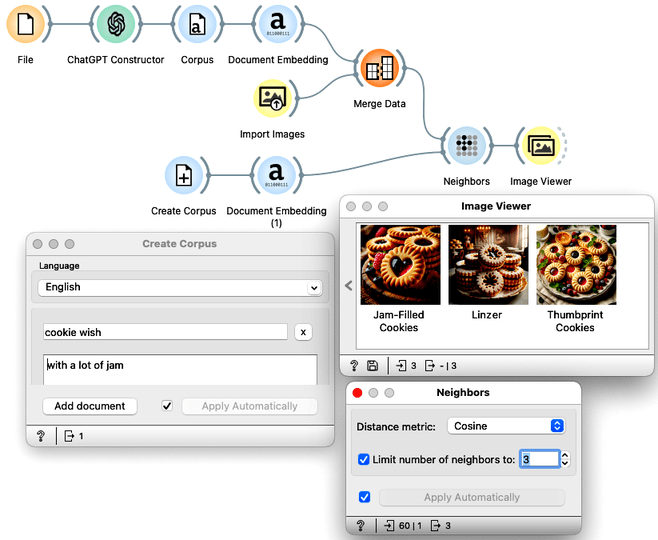
There's only one piece left. Write a wish and figure out which cookie is the best match. To write the wish, we use Create Corpus. We pass the text to the document embedding widget, and then find nearest neighbors in the cookie description embedding space. Again, we use cosine distance and limit the number of neighbors to three. Finally, we use the Image Viewer to display the images of the cookies whose description best matches the text we wrote in Create Corpus.
And that's it. This was not the easiest workflow, but we hope you enjoyed it and especially the video. There, on YouTube, do not forget to subscribe to our Orange Data Mining channel.
Merry Christmas and a Happy New Year!
