text mining, topic modelling, lda, visualization
LDAvis: visualization for LDA topic modelling
Ajda Pretnar Žagar
Mar 18, 2022
Topic modelling is a great way to uncover hidden topics in a large collection of documents. The method is extremely popular in digital humanities, so it is not just about the performance, but also the explainability.
Among topic modelling methods, many researchers still go with LDA, a generative model that observe word frequencies in the corpus and iteratively constructs a topic model for a given number of topics.
Topic Modelling widget computes the LDA topic model. The widget also shows the top 10 words that describe each topic. We construct the below example of grimm-tales-selected, which we loaded with the Corpus widget. Then we preprocess the data with Preprocess Text, where we used the default preprocessing. The most important thing is to add Bag of Words with the TF-IDF transform. LDA works a lot better when using this transform, as it descreases the importance of overly frequent words.
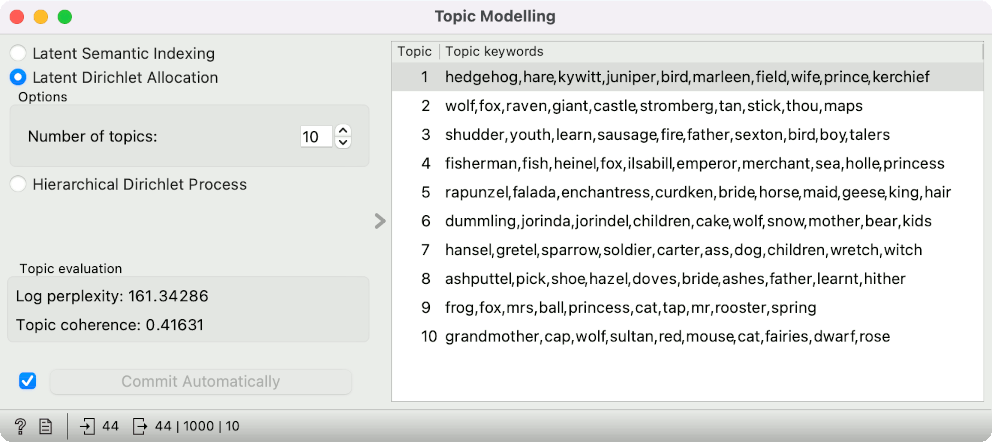
In Topic Modelling we use the LDA method with 10 topics. Ok, the first topic is a about animal tales, even more so the second. The fourth topic is about fish and the tenth topic probably contains the Little Red Riding Hood tale. But how frequent are grandmothers in the corpus overall? Perhaps most tales talk about grandmothers, so the top word for the tenth topic is not really informative.
To explore the relationship between frequent and specific words in the topic, we can use LDAvis (Siever and Shirley 2014). Be careful to connect the right output to the widget. Topic Modelling outputs three things: corpus with topics, the selected topic, and all topics (topic-term matrix). We need last output for LDAvis to work.
LDAvis shows top ranked words for each topic, weighted by relevance. Generally, topic modelling show the top N words by the word's topic probability. In other words, the more frequent is the word in the topic, the higher the word will be on the list.
Relevance defines the relationship between the word's topic probability and its lift. Lift is the ratio of the probability of the word in the topic to the probability of the word in the corpus. The more frequent is the word in the corpus, the lower will be its lift. Hence lift will expose words that appear almost exclusively in the topic.
Relevance is set to 0.5 by default, meaning there will be a balance between the probability of the word in the topic and its lift. Feel free to change the value and explore how the word ranking changes.
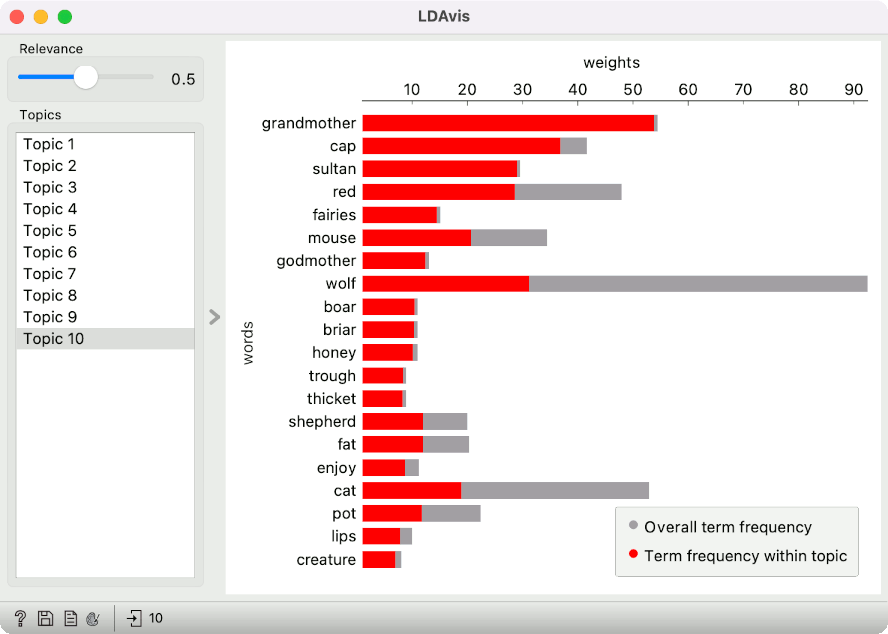
Grandmother from the topic 10 actually seems like it appears almost exlusively in this topic. Wolf, for example, is also characteristic of the topic, but it is quite frequent in the corpus in general.
Siever and Shirley's LDAvis has another component, which shows marginal topic frequency in an MDS projection. Connect All Topics output from Topic Modelling to MDS. The widget will show topics in a 2D projection, where similar topics will lie close together and different topics far apart. Note that topic similarity is based on which words a characteristic of the topic.
Now set the Color and Size attributes to Marginal Topic Probability and Label to Topics. Voila, this is a PCA-initiated MDS projection, where the size of the point corresponds to the marginal topic probability and the position of the point to its similarity with other topics.
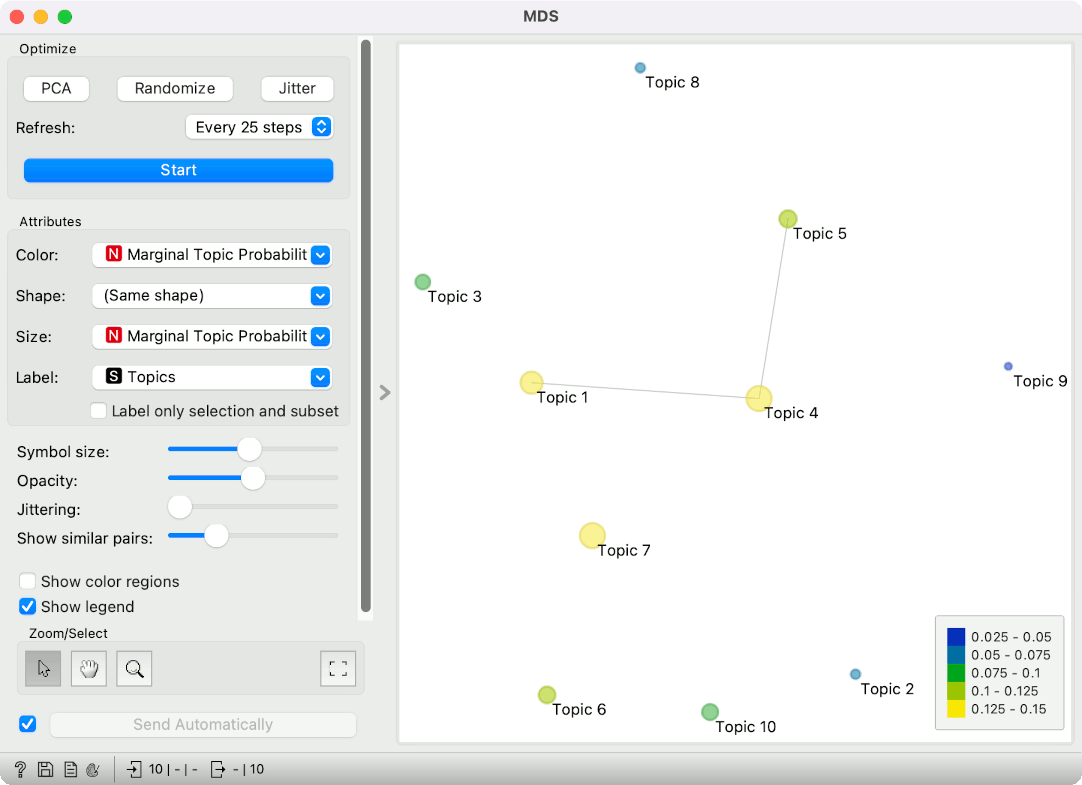
Topic 4, which is about the fish, seems to be quite well-represented in the corpus.
This is it - a quick way to recreate LDAvis in Orange.
References
Sievert, C. and K. E. Shirley. 2014. "LDAvis: A method for visualizing and interpreting topics." Proceedings of the Workshop on Interactive Language Learning, Visualization, and Interfaces, pp. 63–70, Baltimore, Maryland, USA.