orange, education, machine learning
Machine Learning Jargon
Ajda Pretnar Žagar
Feb 01, 2022
We all know each profession has its own jargon. Most of us remember from any hospital series something like: ""Pass me the scalpel, stat!" Meaning "give me the scalpel quickly".
Data scientists are no different. We have our own terminology that requires some getting used to. Here's a list of common terms that we use in machine learning. Some terms are specific to Orange and might not be used elsewhere. The post is intended to get you familiar with concepts used in Orange.

Data
-
variable, also known as attribute or feature (sometimes even predictor). In statistics they would be called independent variables. This all refers to descriptions of data samples. If you have patients in rows, that variables are in columns and they describe these patients (i.e. with name, date of birth, cholesterol level, heart rate, and so on).
-
data sample, also known as data instance. These are the rows in your table and represent the objects or subjects you are researching. For example, patients, passengers on Titanic, species of iris, or a children's fairy tales.
-
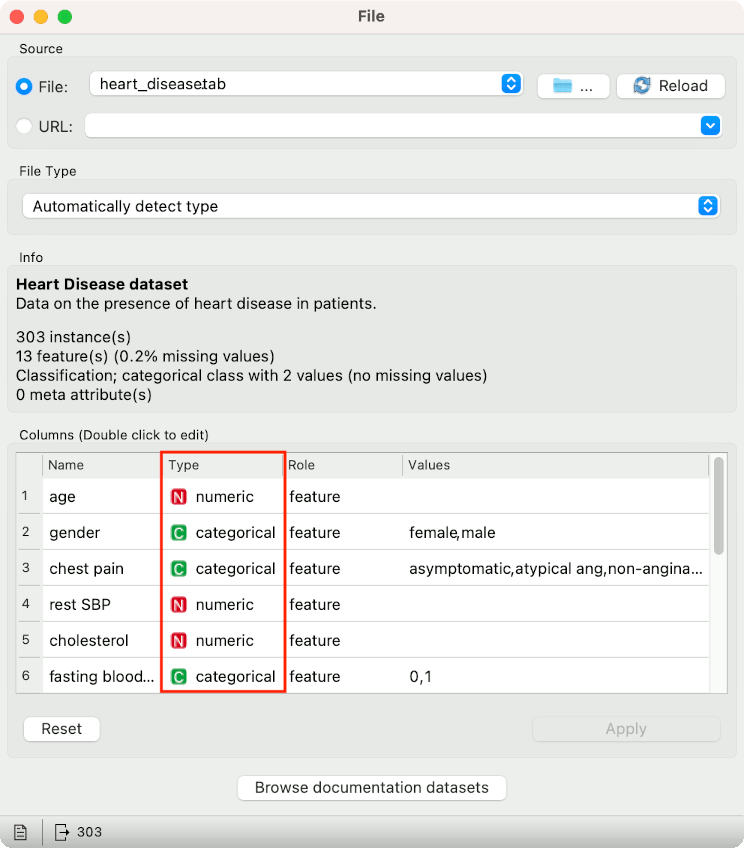
categorical or discrete variable. This refers to a variable with categories as values, for example eye color, nationality, ticket class (first, second, third), and so on. In Orange, these would be marked with a green C.
-
numeric or continuous variable. This refers to a variable with numbers as values, for example cholesterol level, heart rate, age, and so on. In Orange, these would be marked with a red N.
-
string or text variable. This refers to a variable with text as value, for example the address, the ID of a product, or the name of the person. In Orange, these would be marked with a black S. They would always be in meta variables.
-
datetime variable. This refers to a variable with time as value, for example date of birth or time of the event. In Orange, these would be marked with a blue T.
-
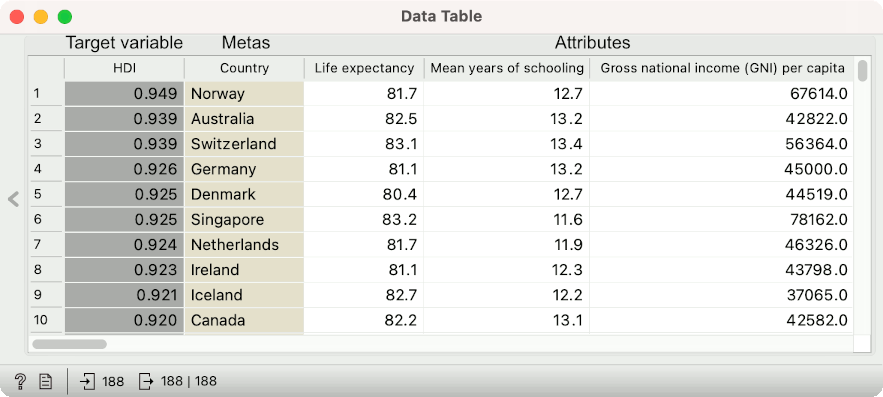
meta variable is a variable that adds additional information on a data sample, but it is not used in computation. Such variables are text variables, but they can also be of other types. For example, if we set the age of the person as a meta variable, this variable will not be considered in clustering or classification. In Orange, they will be marked with beige in a data table.
-
target variable, in statistics known as dependent variable. This is the variable you are trying to predict, for example the survival of Titanic passengers or the price of a house in Boston. In Orange, they will be marked with gray in a data table.
-
class variable is a target variable with categorical values. It is used for classification tasks.
-
domain is something a bit specific to Orange. It contains the information on all the variables in the data set, specifically the type of variables (numeric, categorical, etc.), the role of variables (attributes, metas, target), and the special properties of variables (assigned color, the order of categorical values, etc.).
-
sparse data is a data with many missing values. Such data is usually found in text mining, where among all the words in the corpus, a document would contain only a small amount.
Preprocessing
-
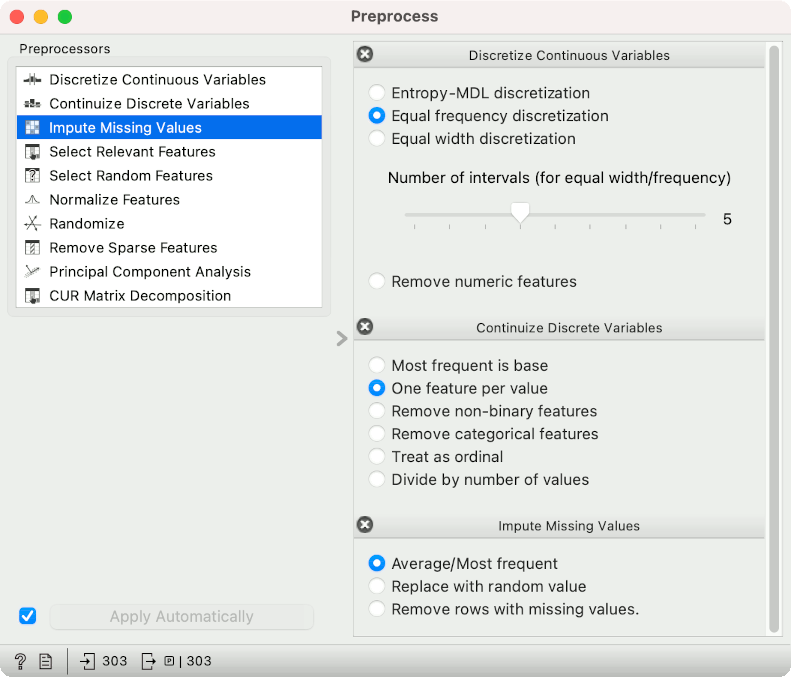
continuize is an operation that transforms categorical variables to numeric, usually by creating a column for each categorical value, i.e. gender=female and giving 1 if female else 0. Many algorithms require numeric data, making continuization extremely important. Orange usually continuizes by default.
-
discretize is an operation that transforms numeric variables to categorical, usually by creating value ranges or bins.
-
impute is an operation that handles missing values. Certain algorithms cannot work with missing data, so the user needs to handle them beforehand. If there are few missing values, such instances would be removed. If there are many missing values, one would usually use imputing a mean or most frequent value. Or one could use an algorithm that works with sparse data.
-
merge is an operation that adds additional columns to the data. For example, we have some patients, and the friendly hospital sends us their records. We can add the records to the patients by matching by the patient ID.
-
concatenate is an operation that add additional rows to the data. For example, we have some patients, and then another 10 patients are admitted to the hospital. We can add them to the table by matching by column names.
Modelling
-
training data is a sample of the data set used for training the model. Usually, this is the larger portion of the data, say 70% or 80% of all data samples.
-
test data is a sample of the data set used for testing the model and evaluating its performance. Usually, this is a smaller portion of the data, say 10%-20% of all data samples.
-
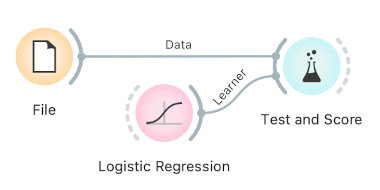
learner is an algorithm (procedure or recipe) for training the model. It is passed to the selected evaluation method, usually to Test and Score widget for cross-validation. It does not contain any data, just the procedure.
-
model is an a result of training the data with a procedure (a learner) and the training data. A model is essentially a set of all recognized patterns in the data relating to the target variable, which are assembled into a final mathemathical function. The model can be used for prediction.
To sum up
We hope you found this informative. This information should help you navigate Orange easily and talk more precisely about your data mining and machine learning tasks.