conllu, text mining, corpus, lemma
New in Orange: Support for CONLL-U files
Ajda Pretnar
Sep 15, 2021
CONLL-U files are ubiquitous in text mining and natural language processing. They can hold a great deal of linguistic data, specifically sentence boundaries, word lemmas, universal POS tags, language specific POS tag, morphological features, dependency relations, named entities, and so on. This is how a typical CONLL-U file looks like.
# sent_id = ParlaMint-GB_2021-01-05-lords.seg2.2
# text = The Hybrid Sitting of the House will now begin.
1 The the DET DT Definite=Def|PronType=Art 2 det _ NER=O
2 Hybrid hybrid NOUN NN Number=Sing 9 nsubj _ NER=O
3 Sitting sit VERB VBG VerbForm=Ger 2 acl _ NER=O
4 of of ADP IN _ 6 case _ NER=O
5 the the DET DT Definite=Def|PronType=Art 6 det _ NER=O
6 House House PROPN NNP Number=Sing 3 obl _ NER=B-ORG
7 will will VERB MD VerbForm=Fin 9 aux _ NER=O
8 now now ADV RB _ 9 advmod _ NER=O
9 begin begin VERB VB VerbForm=Inf 0 root _ NER=O|SpaceAfter=No
10 . . PUNCT . _ 9 punct _ NER=O
Since the release of Text v. 1.5.0, Orange can import CONNL-U files and its textual information. Specifically, Orange will import each utterance as a separate text entity. If selected in import options, it will append lemmas as tokens, POS tags as POS tags, and named entities as a separate text column. It will also add meta information to the imported corpus, if present in the folder.
Here's an example. We are using ParlaMint-GB v2.1 data from CLARIN repository, which contains annotated parliament speeches. Using Import Documents widget, we will import all the sessions for the year 2021.
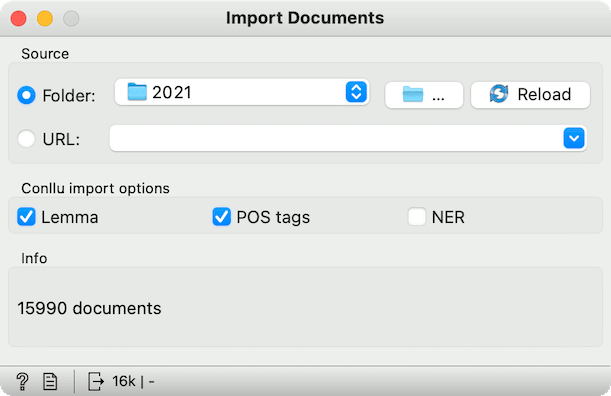
In the widget, we can set which parts of the CONLL-U file will be imported. Let us go with lemmas and POS tags. With this, we don't need preprocessing as usual, as lemmas will be automatically considered downstream (for example in bag of words or topic modeling).
However, the new release of Text also enables us to filter on POS tags. Say we wish to keep only nouns and verbs. We can use Preprocess Text to keep only the specified tags. Remember to remove the default preprocessors as they will override the pre-set tokens.
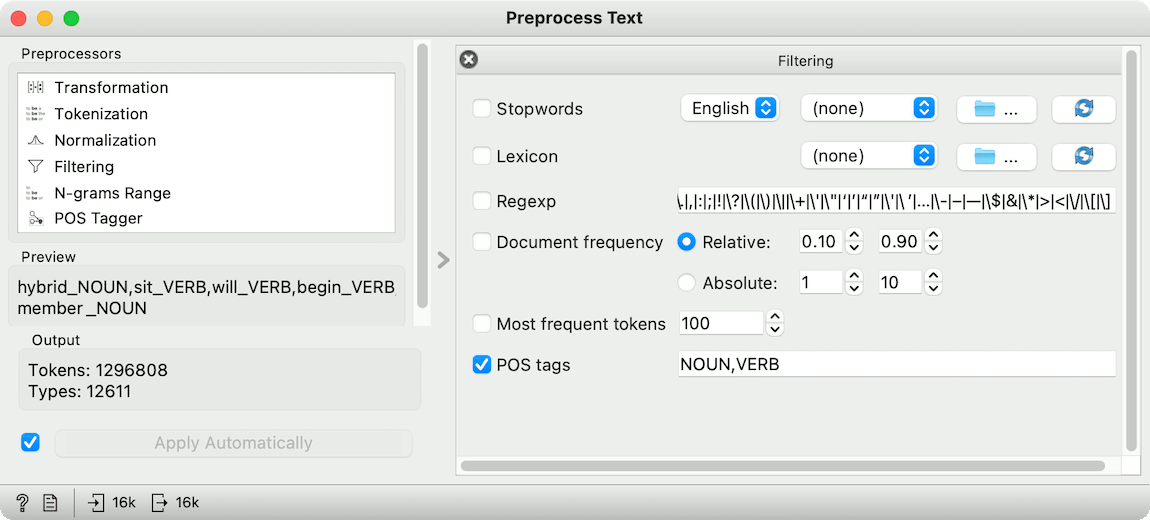
Looking at the Word Cloud, we can see that indeed only verbs and nouns were kept after preprocessing. And not only that! As we have selected to import lemmas, our words will already be normalized. Most of the preprocessing work is done for us! Now you can play with downstream analysis - for example, try to determine which words are significant for which MP using Word Enrichment!