education, teaching, machine learning
Hands-On Training About Overfitting
Blaž Zupan
Mar 05, 2021
PLOS Computation Biology has just published our paper on training about overfitting:
- Demšar J, Zupan B (2021) Hands-on training about overfitting. PLoS Comput Biol 17(3): e1008671.
Machine learning has recently propelled approaches for the analysis of data, but "for the uninitiated, the technology poses significant difficulties" (Deep learning for biology, Nature, Feb 22, 2018). One of the hard concepts for starters in machine learning is overfitting. Overfitting can lead to models that include patterns that do not generalize well and could be meaningless. It is thus vital to include teaching about overfitting in any data science course.
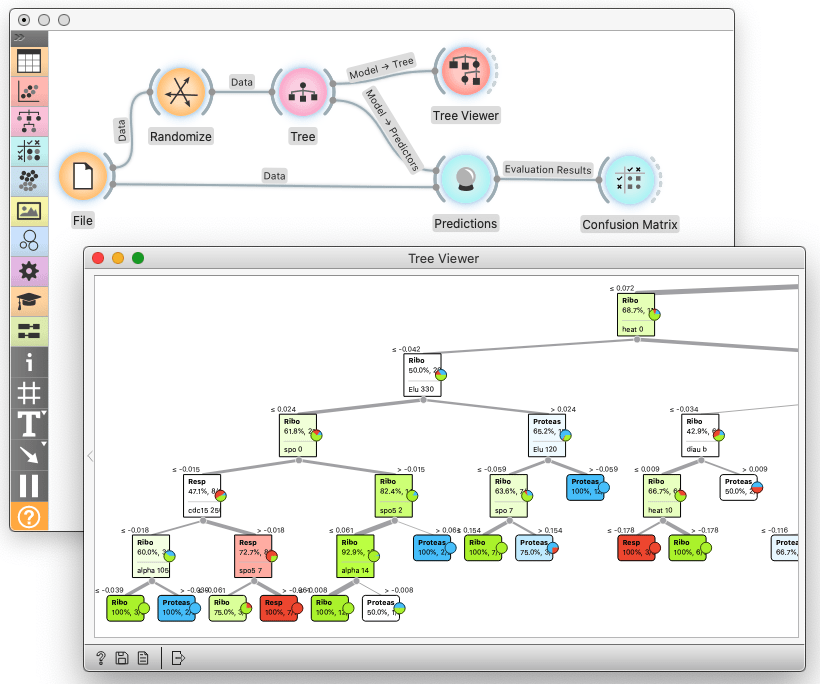
For years, we have been developing Orange, a data science platform. Since we are also educators, we have designed Orange to support the teaching of concepts in machine learning. In the paper, we lay out a short course that uses Orange to teach about overfitting. The specific advantage of our proposed course is that it is entirely hands-on, can be carried out in few hours, does not require any prerequisites or much background knowledge, and is suitable for students of biomedicine or molecular biology that do not necessarily know how to code. The course layout we are proposing is practical; students learn by analyzing the data, making mistakes in the analysis that lead to overfitting, and correcting these by adjusting the workflows.
In the past several years, we have been giving and perfecting the lecture we are reporting in the paper. The lecture is carried out yearly at the University of Ljubljana, Slovenia, and at Baylor College of Medicine in Houston. The lecture was also included in over 50 short hands-on courses on machine learning we have been giving around the world. Our paper reports on the course structure, pedagogical principles we use in teaching, and a walk through the course that educators can use for teaching material and ideas within their lessons.
Our other manuscripts, where we report on Orange as a tool for education in data science, include
- Stražar M, Žagar L, Kokošar J, Tanko V, Erjavec A, Poličar P, Starič A, Demšar J, Shaulsky G, Menon V, Lamire A, Parikh A, and Zupan B (2019) scOrange – A Tool for Hands-On Training of Concepts from Single Cell Data Analytics, Bioinformatics 35(14):i4-i12.
- Godec P, Pančur M, Ilenič N, Čopar A, Stražar M, Erjavec A, Pretnar A, Demšar J, Starič A, Toplak M, Žagar L, Hartman J, Wang H, Bellazzi R, Petrovič U, Garagna S, Zuccotti M, Park D, Shaulsky G, Zupan B (2019) Democratized image analytics by visual programming through integration of deep models and small-scale machine learning, Nature Communications 10(1):4551.