text mining, corpus, classification
How to identify fake news with document embeddings
Primož Godec and Nikola Đukić
Oct 15, 2020
Text is described by the sequence of character. Since every machine learning algorithm needs numbers, we need to transform it into vectors of real numbers before we can continue with the analysis. To do this, we can use various approaches. Orange currently offers bag-of-words approach and now also Document embedding by fastText. In this post, we explain what document embedding is, why it is useful, and show its usage on the classification example.
Word embedding and document embedding
Before we understand document embeddings, we need to understand the concept of word embeddings. Word embedding is a representation of a word in multidimensional spaces such that words with similar meanings have similar embedding. It means that each word is mapped to the vector of real numbers that represents the word. Embedding models are mostly based on neural networks.
Document embedding is computed in two steps. First, each word is embedded with the word embedding then word embeddings are aggregated. The most common type of aggregation is the average over each dimension.
Why and when should we use embedders?
Compared to bag-of-words, which counts the number of appearances of each token in the document, embeddings have two main advantages:
- They do not have a dimensionality problem The result of bag-of-words is a table which has the number of features equal to the number of unique tokens in all documents in a corpus. Large corpora with long texts result in a large number of unique tokens. It results in huge tables which can exceed memory in the computer. Huge tables also increase the learning and evaluation time of machine learning models. Embedders have constant dimensionality of the vector, which is 300 for fastText embeddings that Orange uses.
- Most of the preprocessing is not required In case of bag-of-words approach, we solve the dimensionality problem with the text preprocessing where we remove tokens (e.g. words) that seem to be less important for the analysis. It can also cause the removal of some important tokens. When using embedders, we do not need to remove tokens, so we are not losing the accuracy this way. Also most of the basic preprocessing can be omitted (such as normalization) in case of fastText embeddings.
- They can be pretrained Word embedding models can be pretrained on large corpora with billions of tokens. That way, they capture the significant characteristics of the language and produce the embeddings of high quality. Pretrained models are then used to obtain embeddings of smaller datasets. Our Document Embedding widget uses pretrained fastText models and is suitable for corpora of any size.
The shortcoming of the embedders is that they are difficult to understand. For example, when we use a bag-of-words, we can easily observe which tokens are important for classification with Nomogram widget since tokens themselves are features. In the case of document embeddings, features are numbers which are not understandable to human by themselves.
Document Embedding widget
Orange now offers document embedders through Document Embedding widget. We decided to use fastText pretrained embedders, which support 157 languages. Orange's Document Embedding widget currently supports 31 most common languages.
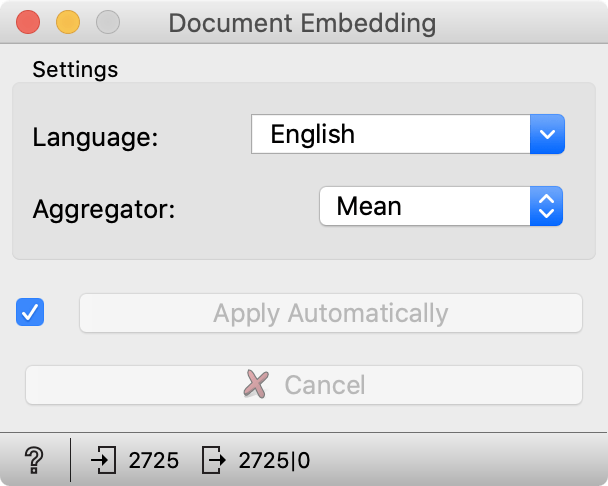
In the widget, the user sets the language of documents and the aggregation method -- it is how embeddings for each word in a document are aggregated into one document embedding.
The Fake News dataset
For this tutorial, we use the sample of Fake News dataset. The dataset sample is available at Orange's file repository. It is a zip archive containing two datasets: training set including 2725 text items and testing set with 275 items. Each item is an article which is labelled as a real or fake.
Fake news identification
Here we present a fake news identification. First, we will load a training part of the dataset with the Corpus widget.
After the dataset is loaded, we make sure that the text variable is selected in the Used text features field. It means that the text in this variable is used in the text analysis. When the dataset is loaded we connect the Corpus widget to the Document embedder widget which will compute text embeddings. Our workflow should look like this now:
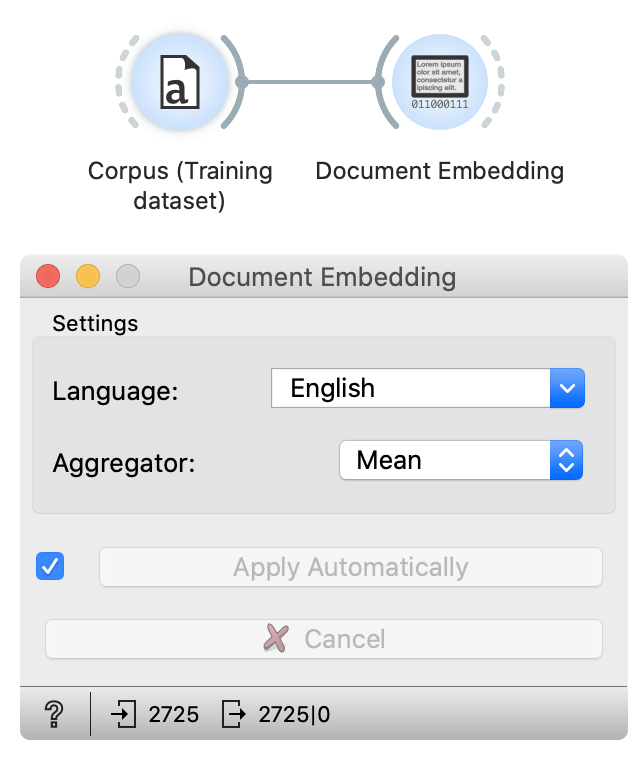
In the document embeddings widget, we check that language is set to English since texts in this dataset are English. We will use mean (average) aggregation in this experiment -- it is the most standard one. After minute documents are embedded -- embedding progress is shown with the bar around the widget.
When embeddings are ready, we can train models. In this tutorial, we train two models -- Logistic regression and Random forest. We will use default settings for both learners.
When our models are trained, we prepare the testing data. To load testing data, we use another Corpus widget and connect it to the Document embedder widget. Settings are the same as before. The only difference is that this time we load testing part of the dataset in the second Corpus widget. To make predictions and inspect the prediction results on the testing dataset, we use the prediction widget.
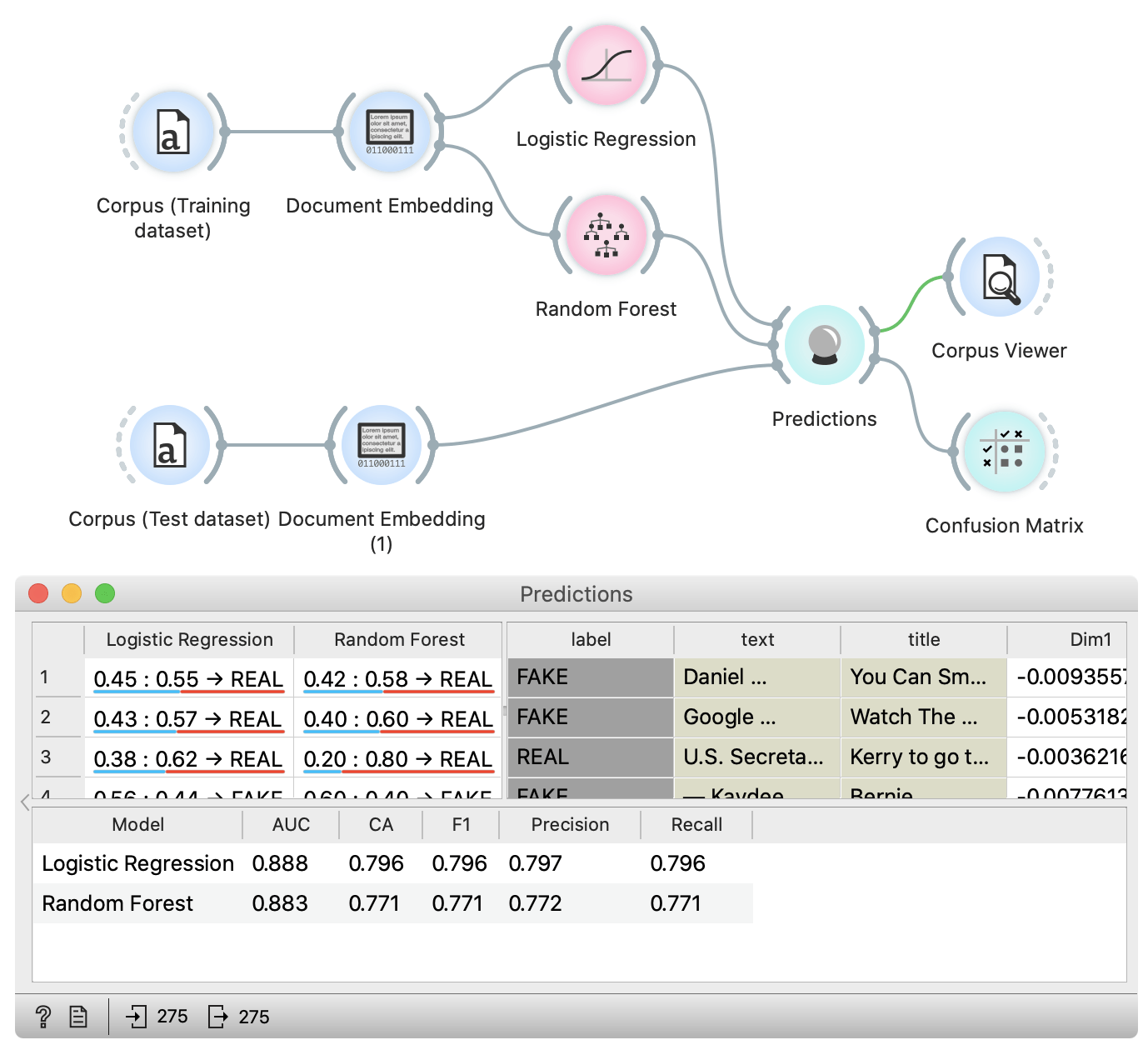
In the bottom part of the widget, we inspect the accuracies. In the column with name CA (classification accuracy), we can see that both models perform with around 80 % accuracy. In the table above, we can find cases where models made mistakes. If we select rows, we can check them in the Corpus Viewer widget which is connected to the Predictions widget. We have also connected the confusion matrix widget to our workflow, which shows the proportions between the predicted and actual classes.
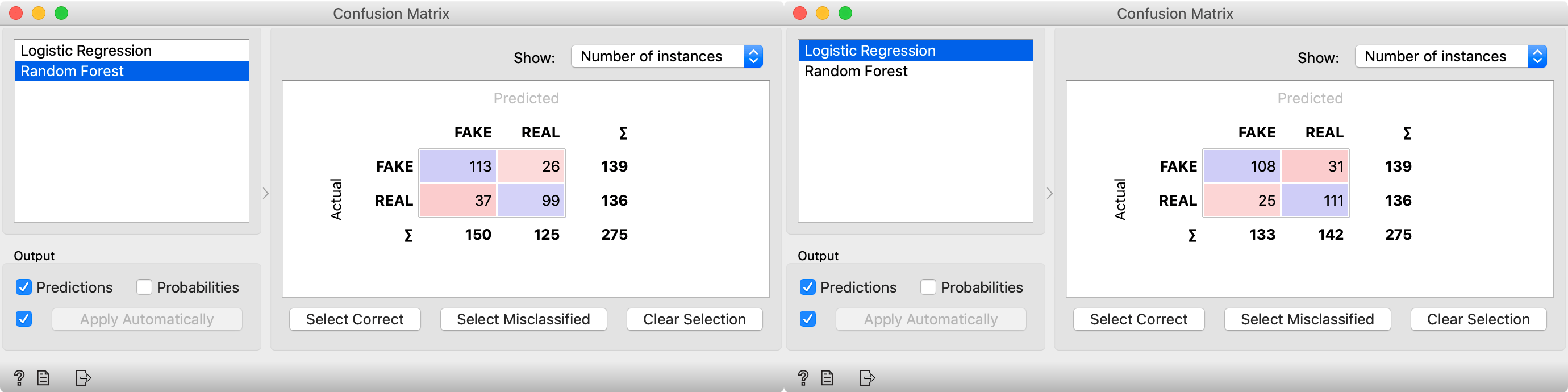
We can see that Logistic regression is slightly more accurate in cases of real news while Random forest model is better for predicting fake news.
It is just one example which shows how to use document embeddings. You can also use them for other tasks such as clustering, regression or other types of analysis.