cross validation, leave one out, LOO, test and score
The Mystery of Test & Score
Ajda Pretnar
Jan 28, 2019
Test & Score is surely one the most used widgets in Orange. Fun fact: it is the fourth in popularity, right after Data Table, File and Scatter Plot. So let us dive into the nuts and bolts of the Test & Score widget.
The widget generally accepts two inputs – Data and Learner. Data is the data set that we will be using for modeling, say, iris.tab that is already pre-loaded in the File widget. Learner is any kind of learning algorithm, for example, Logistic Regression. You can only use those learners that support your type of task. If you wish to do classification, you cannot use Linear Regression and for regression you cannot use Logistic Regression. Most other learners support both tasks. You can connect more than one learner to Test & Score.
\
\
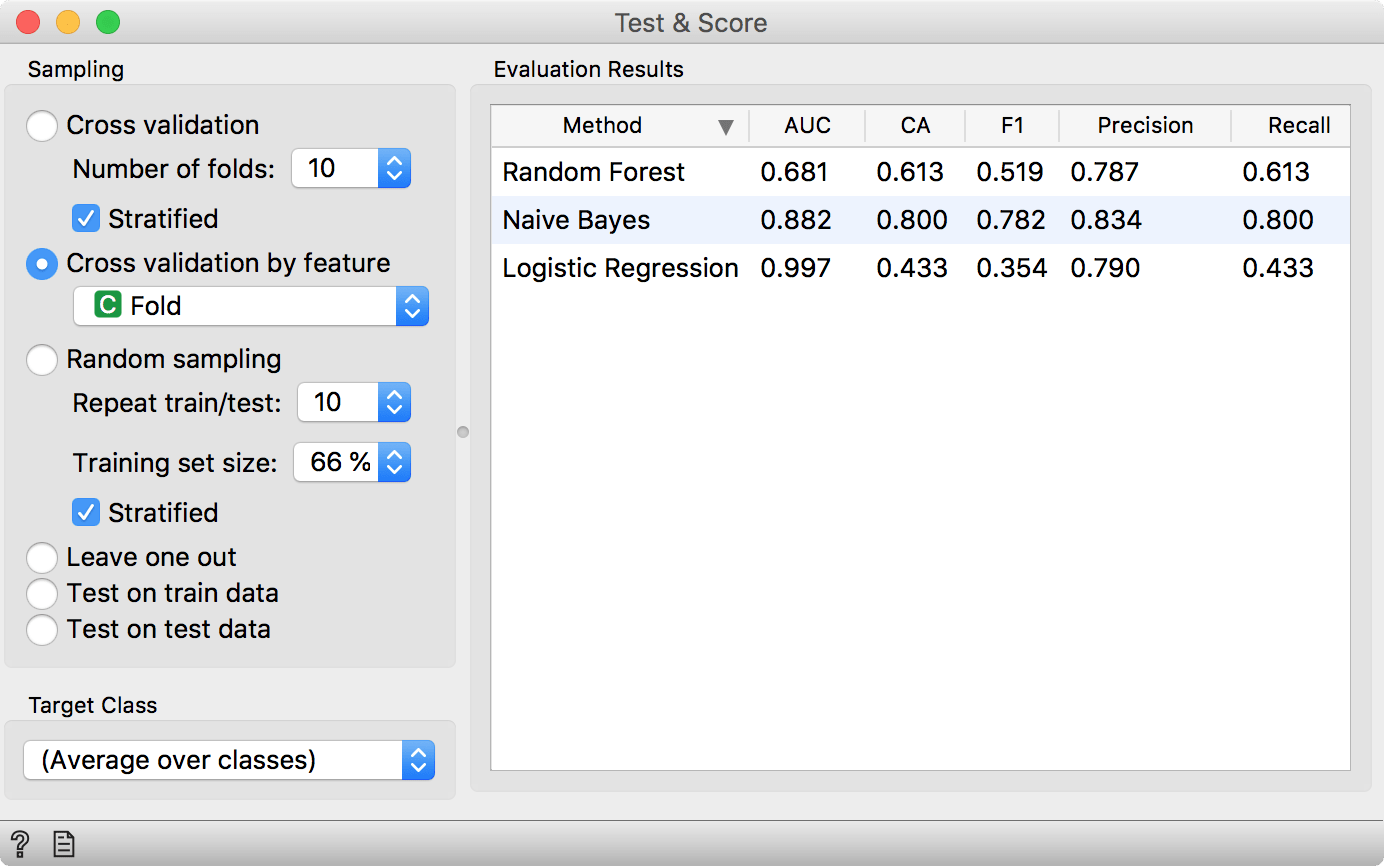
Test & Score will now use each connected Learner and the Data to build a predictive model. Models can be built in different ways. The most typical procedure is cross validation, which splits the data into k folds and uses k – 1 folds for training and the remaining fold for testing. This procedure is repeated, so that each fold has been used for testing exactly once. Test & Score will then report on the average accuracy of the model.
You can also use Random Sampling, which will split the data into two sets with predefined proportions (e.g. 66% : 34%), build a model on the first set and test it on the second. This is similar to CV, except that each data instance can be used more than once for testing.
Leave one out is again very similar to the above two methods, but it only takes one data instance for testing each time. If you have a 100 data instances, then 99 will be used for training and 1 for testing, and the procedure will be repeated a 100 times until every data instance was used once for testing. As you can imagine, this is a very time-intensive procedure and it is recommended for smaller data sets only.
Test on train data uses the whole data set for training and again the same data for testing. Because of overfitting, this will usually overestimate the performance! Test on test data requires an additional data input (Test Data) and allows the user to control both data sets (training and testing) used for evaluation.
Finally, you can also use cross validation by feature. Sometimes, you would have pre-defined folds for a procedure, that you wish to replicate. Then you can use Cross validation by feature to ensure data instances are split into the same folds every time. Just make sure the feature you are using for defining folds is a categorical variable and located in meta attributes.
Another scenario is when you have several examples from the same object, for example several measurements of the same patient or several images of the same plant. Then you absolutely want to make sure that all data instances for a particular object are in the same fold. Otherwise, your model would probably report severely overfitted scores.
\
\