preprocessing, text mining
Orange Now Speaks 50 Languages
AJDA
Oct 05, 2018
In the past couple of weeks we have been working hard on introducing a better language support for the Text add-on. Until recently, Orange supported only a limited number of languages, mostly English and some bigger languages, such as Spanish, German, Arabic, Russian... Language support was most evident in the list of stopwords, normalization and POS tagging.
Related: Text Workshops in Ljubljana
Stopwords come from NLTK library, so we can only offer whatever is available there. However, TF-IDF already implicitly considers stopwords, so the functionality is already implemented. For POS tagging, we would rely on Stanford POS tagger, that already has pre-trained models available.
The main issue was with normalization. While English can do without lemmatization and stemming for simple tasks, morphologically rich languages, such as Slovenian, perform poorly on un-normalized tokens. Cases and declensions present a problem for natural language processing, so we wanted to provide a tool for normalization in many different languages. Luckily, we found UDPipe, a Czech initiative that offers trained lemmatization models for 50 languages. UDPipe is actually a preprocessing pipeline and we are already thinking about how to bring all of its functionality to Orange, but let us talk a bit about the recent improvements for normalization.
Let us load a simple corpus from Corpus widget, say grimm-tales-selected.tab that contain 44 tales from the Grimm Brothers. Now, pass them through Preprocess Text and keep just the defaults, namely lowercase transformation, tokenization by words, and removal of stopwords. Here we see that we have came as quite a frequent word and come as a bit less frequent. But semantically, they are the same word from the verb to come. Shouldn't we consider them as one word?
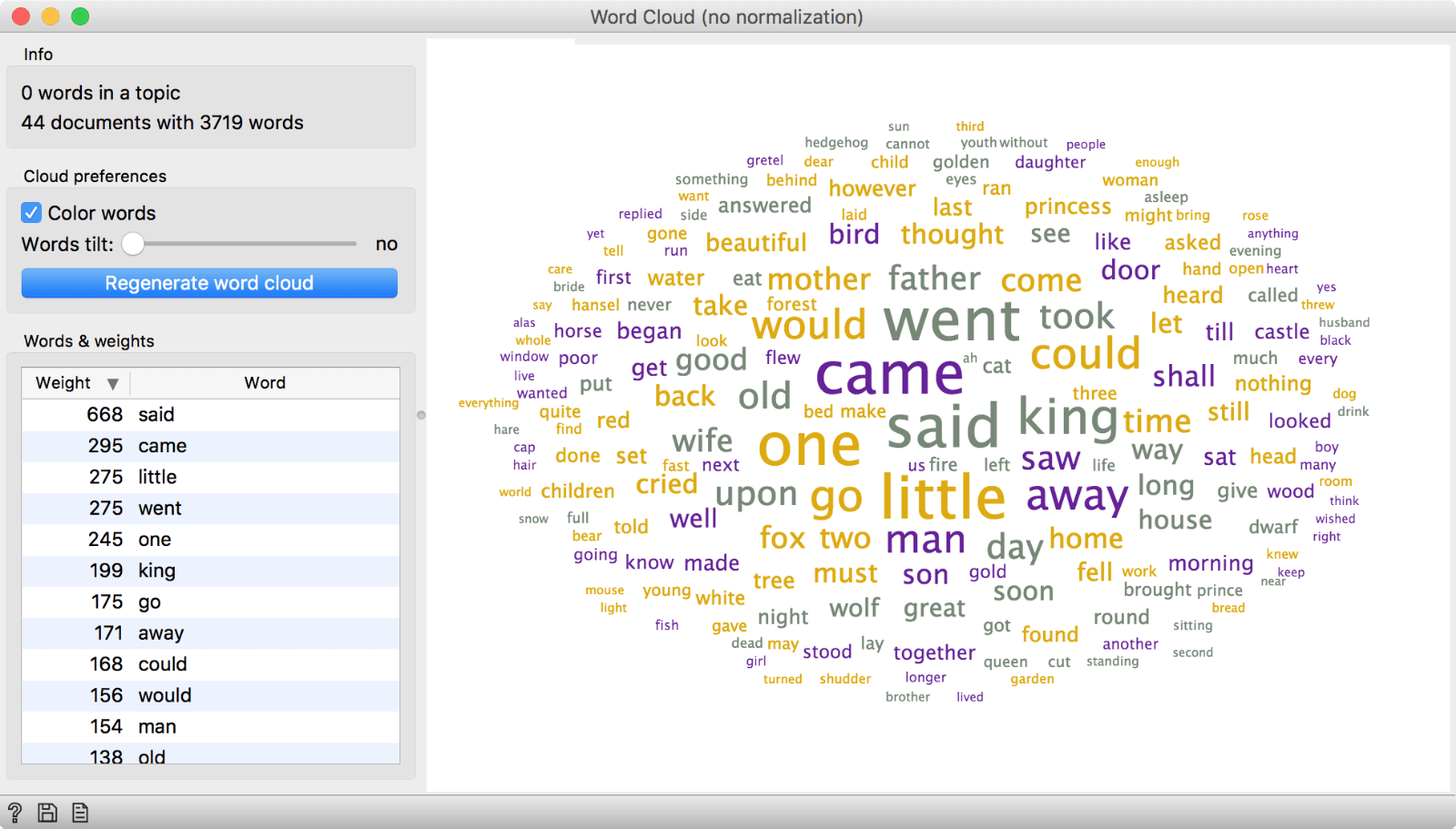
We can. This is what normalization does - it transforms all words into their lemmas or basic grammatical form. Came and come will become come, sons and son will become son, pretty and prettier will become pretty. This will result in less tokens that capture the text better, semantically speaking.
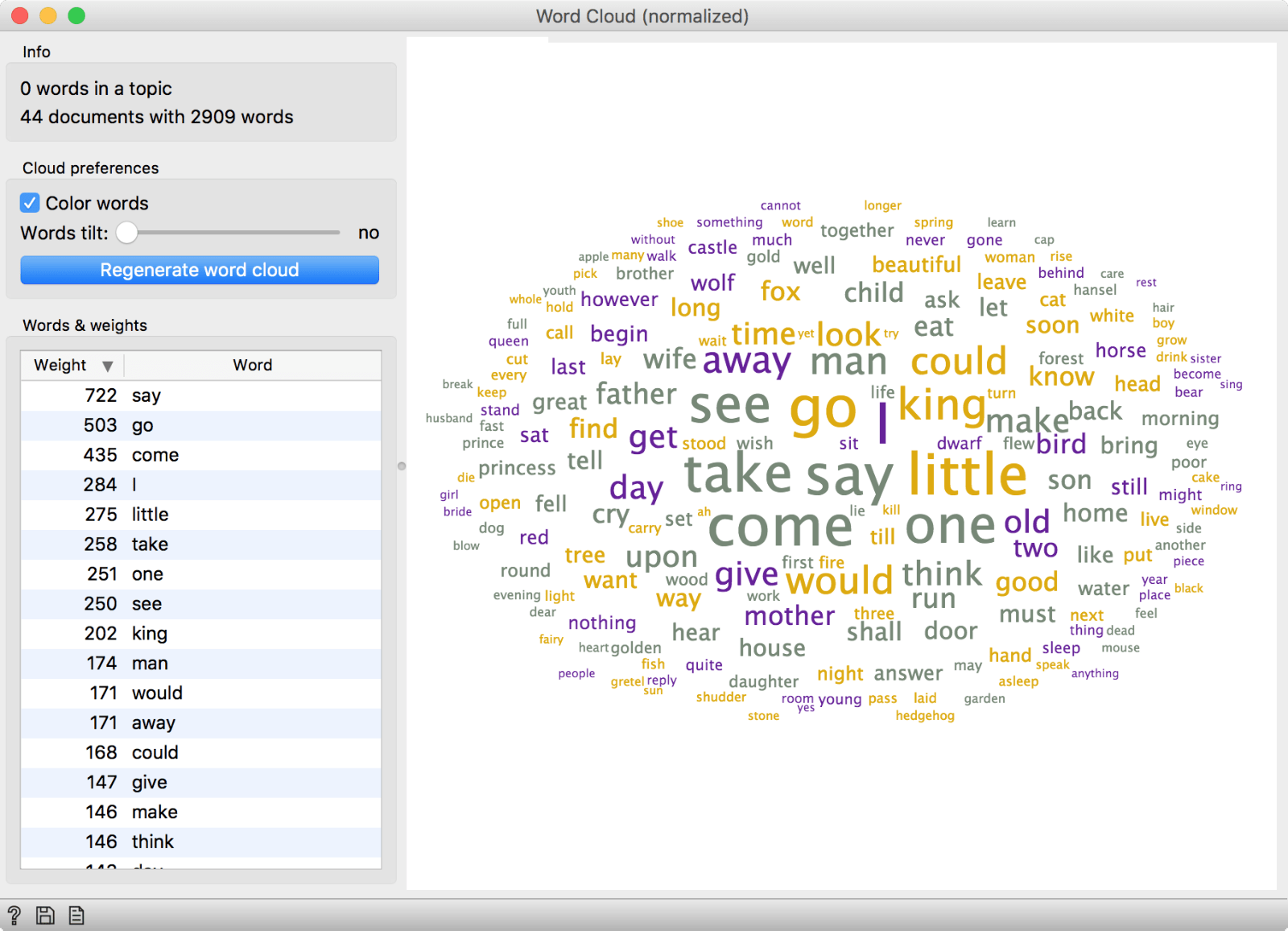
We can see that came became come with 435 counts. Went became go. Said became say. And so on. As we said, this doesn't work only on verbs, but on all word forms.
One thing to note here. UDPipe has an internal tokenizer, that works with sentences instead of tokens. You can enable it by selecting UDPipe tokenizer option. What is the difference? A quicker version would be to tokenize all the words and just look up their lemma. But sometimes this can be wrong. Consider the sentence:
I am wearing a tie to work.
Now the word tie is obviously a piece of clothing, which is indicated by the word wearing before it. But tie alone can also be the verb to tie. So the UDPipe tokenizer will consider the entire sentence and correctly lemmatize this word, while lemmatization on regular tokens might not. While UDPipe works better, it is also slower, so you might want to work with regular tokenization to speed up the analysis.
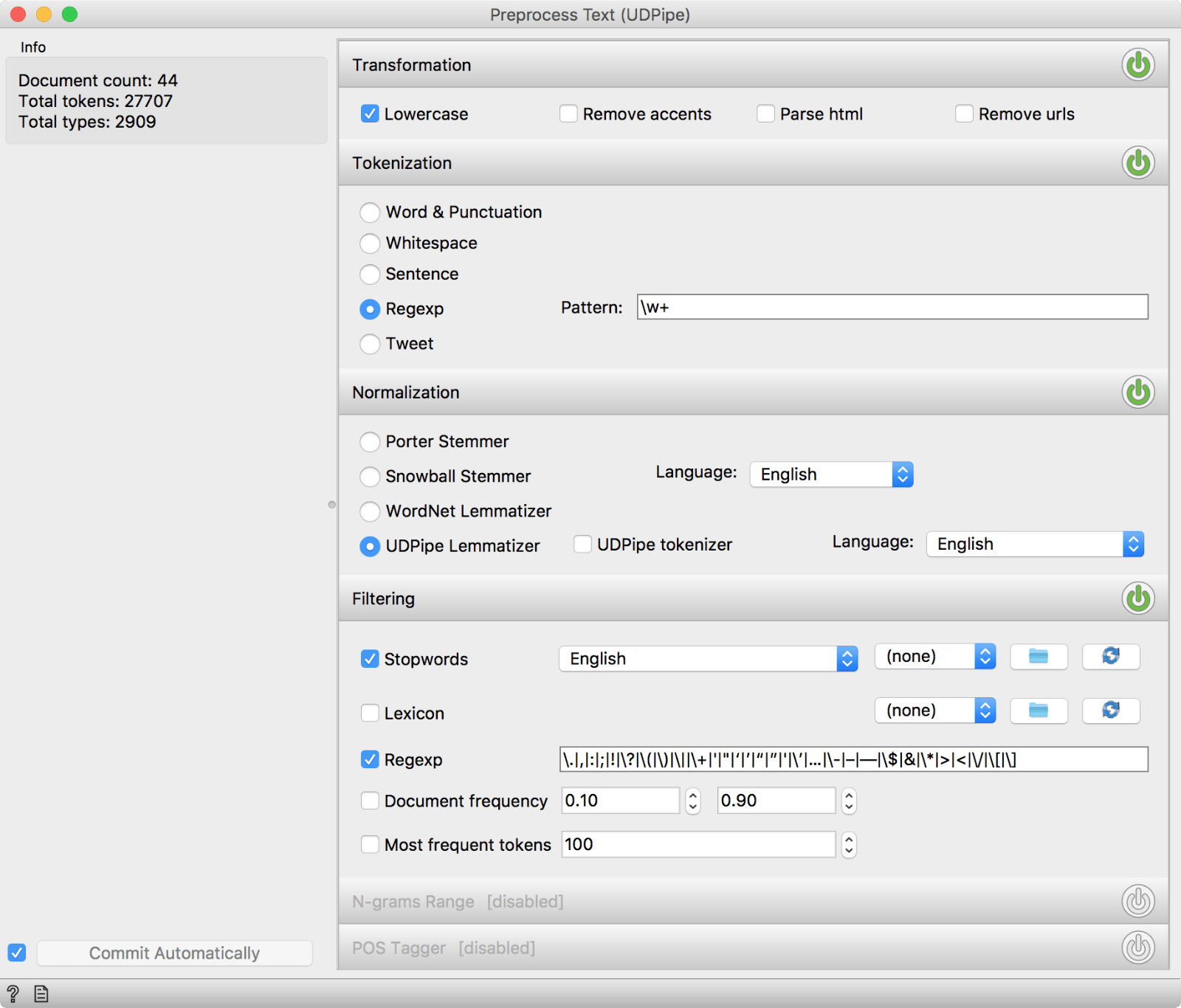 In Preprocess Text, you turn on the Normalization button on the right, then select UDPipe Lemmatizer and select the language you wish to use. Finally, if you wish to go with the better albeit slower UDPipe tokenizer, tick the UDPipe tokenizer box.
In Preprocess Text, you turn on the Normalization button on the right, then select UDPipe Lemmatizer and select the language you wish to use. Finally, if you wish to go with the better albeit slower UDPipe tokenizer, tick the UDPipe tokenizer box.
Finally, UDPipe does not remove punctuation, so you might end up with words like rose. and away., with the full stop at the end. This you can fix with using regular tokenization and also by select the Regex option in Filtering, which will remove pure punctuation.
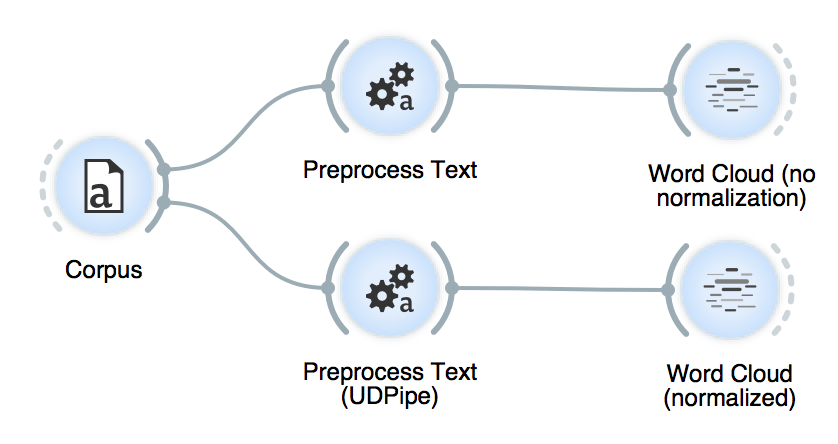 Final workflow, where we compared the results of no normalization and UDPipe normalization in a word cloud.
Final workflow, where we compared the results of no normalization and UDPipe normalization in a word cloud.
This is it. UDPipe contains lemmatization models for 50 languages and only when you click on a particular language in the Language option, will the resource be loaded, so your computer won't be flooded with models for languages you won't ever use. The installation of UDPipe could also be a little tricky, but after some initial obstacles, we have managed to prepare packages for both pip (OSX and Linux) and conda (Windows).
We hope you enjoy the new possibilities of a freshly multilingual Orange!