classification, features, interface, orange3, prediction, predictive analytics, regression, toolbox, update
Model replaces Classify and Regression
AJDA
Apr 07, 2017
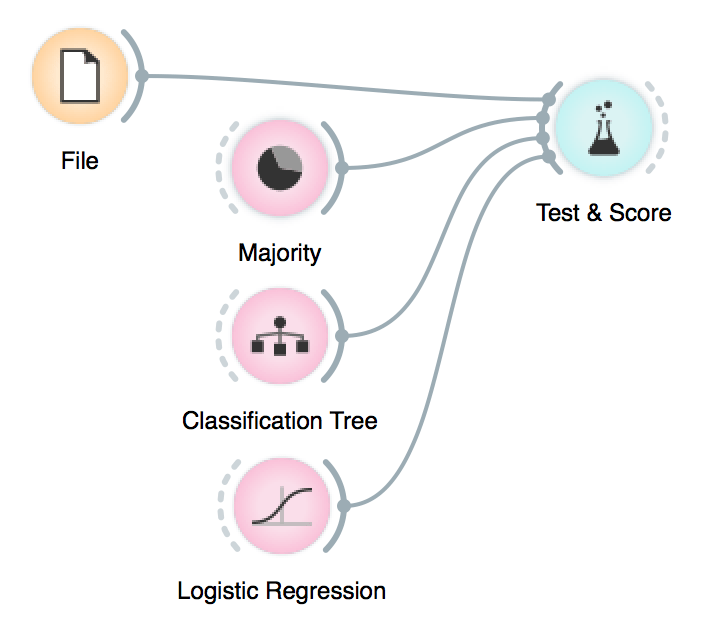
Did you recently wonder where did Classification Tree go? Or what happened to Majority?
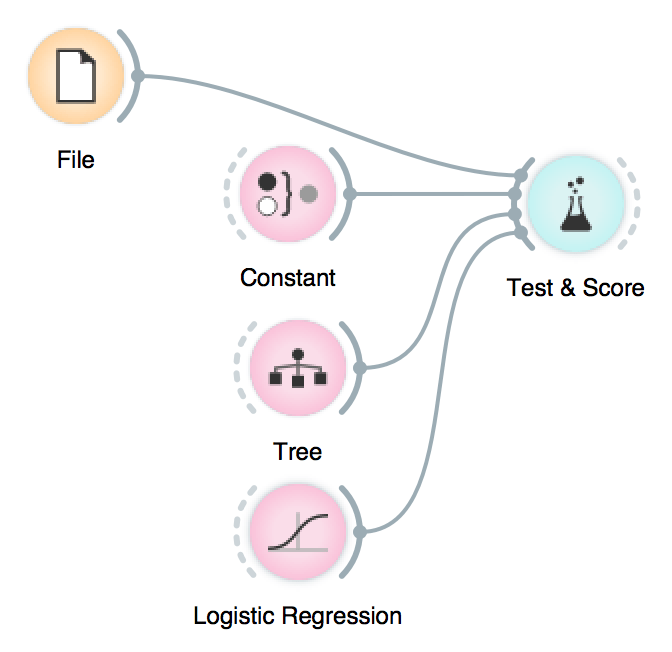
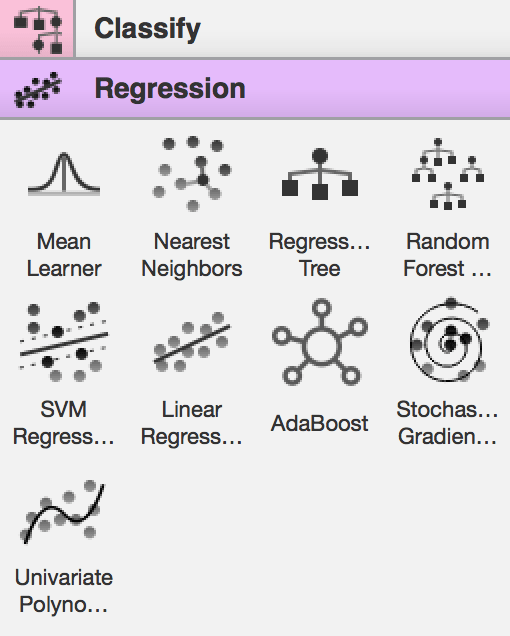
Orange 3.4.0 introduced a new widget category, Model, which now contains all supervised learning algorithms in one place and replaces the separate Classify and Regression categories.

This, however, was not a mere cosmetic change to the widget hierarchy. We wanted to simplify the interface for new users and make finding an appropriate learning algorithm easier. Moreover, now you can reuse some workflows on different data sets, say housing.tab and iris.tab!
Leading up to this change, many algorithms were refactored so that regression and classification versions of the same method were merged into a single widget (and class in the underlying python API). For example, Classification Tree and Regression Tree have become simply Tree, which is capable of modelling categorical or numeric target variables. And similarly for SVM, kNN, Random Forest, …
Have you ever searched for a widget by typing its name and were confused by multiple options appearing in the search box? Now you do not need to decide if you need Classification SVM or Regression SVM, you can just select SVM and enjoy the rest of the time doing actual data analysis!
Here is a quick wrap-up:
- Majority and Mean became Constant.
- Classification Tree and Regression Tree became Tree. In the same manner, Random Forest and Regression Forest became Random Forest.
- SVM, SGD, AdaBoost and kNN now work for both classification and regression tasks.
- Linear Regression only works for regression.
- Logistic Regression, Naive Bayes and CN2 Rule Induction only work for classification.
Sorry about the last part, we really couldn’t do anything about the very nature of these algorithms! :)